Warning: a few sections have small to medium rants about higher education (in North America). The point is not my displeasure: the experiences that fueled them, especially if you’ve had similar ones as a graduate student or professor, serve as a stark contrast to further highlight the absolutely incredible accomplishment that is Neuromatch Academy. That being said, how NMA happened needs no backdrop of conventional institutional mediocrity to shine, but it certainly showed me what was possible for higher educations and summer schools moving forward.
TL;DR: it was nothing short of inspiring to witness and to be a tiny part of this summer school, and I learned so much as a TA that I feel bad getting paid. Highly recommend. In the sections below, I recount my experiences as:
- a content reviewer: what impressed me about the organization,
- a TA: what worked pedagogically as a summer school, and
- a student: the coherent picture of computational neuroscience I took away from the NMA curriculum.
Shoutout to my wonderful pod: the Ethereal Ponies, and Sean’s serial killer note logo.
Higher Education Today
Having been an undergraduate student for 5 years, then a TA for 5 more, and eventually an instructor for my own course, all at research-focused institutions, I’m a bit disillusioned when it comes to teaching. It’s not that I haven’t experienced good teaching - I absolutely have. I’ve had the good fortune of being friends and colleagues with some people who care deeply about good and accessible education, and I’ve taken and TAed for classes where professors clearly put students first. However, time and time again, that has been the exception within institutions, not the norm.
Having been a PhD student, of course I understand the plight of the scientist-professor: if we suddenly had 20 more hours a week for free, sure, we might think more deeply about pedagogy for our 200-person class. But without that, how much time we actually dedicate to it is simply a function of what we choose to prioritize. The institution, whatever this monolithic word even means at this point, provides little incentive and meaningful feedback for instructors to teach well. Actually, no - the sole emphasis on research in many places actively discourages one to teach better than the minimally acceptable thing under the current norm. So, if we had 20 more hours a week, we’d spend it on research, because that’s what gets tenures and prints papers (figuratively and literally). I’ve also heard professors actively discouraging their grad students to not spend more time than necessary on TA duties because their main job is to do research, and the sad part is that that’s absolutely in the best interest of their student’s career in academia. It’s just the norm now: the better teacher you try to be, the more time you spend not doing research, and the more often you are undervalued. And this is not even going into adjunct professors and lecturers.
Ironically, the R1 institution is a business whose top product is a good education, and I’m not sure if our customers are getting their money’s worth. This cannot be more perfectly summarized than by this recent letter from some UCSD faculties that details their perspective through the ever-increasing enrollment while not being provided with sufficient resources to deliver quality education to their students. In my first year at UofT, we had a world-class research professor lecture for an intro bioengineering class, and I shit you not, they were late to class more often than I was, which is hard. This system doesn’t only produce uninspired teaching, it produces uninspired students. I really believe that the majority of students going into college want to learn something interesting, even if they were encouraged by their families to follow a more traditional career path. But it only takes so many 300-person lectures for you to realize that there’s no way that person standing up there is going to know your name, nor do they care to, so just give me my A and let’s all get on our way.
This is my (perhaps extremely cynical) perception of higher education as a scientist, and I’m a little tired of it. I’m tired for the people that are time and time again the minority actively choosing to fight the uphill battle to prioritize teaching because they believe it’s the right thing to do. I’m tired for the students that pay for a world class education and get some uninspiring curriculum. The worst part is, after all this time, I get it - under the current system of priorities, that’s the natural equilibrium, and I’ve kind of accepted that that’s just the way it is if you care about pedagogy as a research scientist, and it’s a weird realization to think that one is a part of a niche community for doing the job they are paid for. Maybe it wasn’t that way 20 years ago, but it is that way now. It’s not really anybody’s fault, and it was kind of okay for a while, until a pandemic came to stress test both the financial and educational aspects of our current system, revealing the inner workings of these institutions and what they must to in response to keep the businesses afloat.
I bring all this up to serve as a contrast: contextualized in the systemic inertia of underemphasizing and undervaluing good teaching, how much could a ragtag team of volunteers within that system—all of whom are under the same constraints of their regular research duties, teaching load, industry job, and other administrative duties, during a once-in-a-lifetime COVID pandemic—accomplish in 4 months, attempting to set up the biggest interactive online summer school to date?
Neuromatch Academy
Turns out, a fucking whole lot. Against the backdrop of my cynicism, this whole thing has been nothing short of inspiring to witness and be a part of. The sheer effort and person-hours put in by these people—organizing, producing the content, and mentoring, all for free—is just mind-boggling. But it is only dwarfed by the quality of the curriculum and the students’ overwhelming responses to being a part of the community. Blowing things up and starting over is rarely the best course of action, but I genuinely believe that this will be (at least partially) the gold standard for computational training for summer schools, and potentially for university curriculum altogether. All it took is for a bunch of people that care deeply about teaching and learning computational neuroscience to make this community where focus on pedagogy and student experience is not the exception, but the norm. It’s hard to not feel like I’m proselytizing for NMA at this point. Of course, many parts of it are inspired by education research and existing summer school layouts, while other aspects could be better in future iterations. But I really hope and believe that this program, and this model of teaching, is here to stay.
I don’t think I have a lot of unique insight or information to offer that hasn’t already been covered in one of the debrief sessions during the course, and I highly recommend checking out the NMA logistics and final wrap up videos to see what the behind-the-scenes process was like (some images in this post are taken directly from them). Nevertheless, the following is a report of my month-long journey with NMA, through the lens of a few different roles—waxer (content polisher), TA, and (accidental) student—and what I learned in each. I journaled most of these thoughts along the way, and the purpose of it is really to highlight aspects of this summer school that blew me away, things that worked well and things that could be improved for the future, as well as to provide a little more context for what computational neuroscience is (as presented in those 3 weeks) in the grande scheme of neuroscience and cognitive science.
As a Waxer: Content & Scheduling Logistics
The majority of NMA content is delivered to the students via tutorial Jupyter notebooks. A “waxer”, in NMA lingo, is a person that checks and polishes these notebooks before shipping, after high-level content decisions and coding exercises have been more or less finalized by the content creators of that day, which is itself a multi-step process (outlined below). I wasn’t familiar with any of this, neither were most TAs I think, because there’s no reason to be, it wasn’t part of my job. I somehow just assumed that these notebooks would pop out of thin air, perfectly organized and ready for students to use, which was dumb because I literally went through this process for my own class last summer. That was…non-trivial, and I only had to make 4 Jupyter notebooks for lab for 30 people, which ended up taking like 2 weeks of solid work to do, with no embedded videos, coordination between multiple teams, and more than a handful of bugs in the final product. But because of that experience, I was recruited to help with polishing these notebooks, so I was privy to the inner workings of NMA a couple of weeks before class officially started, and boy was that eye-opening. Stunning, probably, was the better word. As in, I was literally stunned when I joined the team Slack, scrolling through the different channels and witnessing the bustling activity 2 weeks before NMA started. This was a direct quote from my notes:
“Patrick brought me on as a waxer on June 25, I was kind of stunned at just how much of a monster effort it was, from rounding up speakers for their videos, making and waxing tutorial notebooks, cleansing content of CC materials, etc. When I say stunned, I mean literally I was just sitting there going through all the docs to try to wrap my head around the organizational structure. Insane workload and insanely inspiring that these people were putting in so much time and effort to make this thing run, and most of which more senior than me personally.”
It’s like one of those movie scenes, where you get invited to Charlie’s chocolate factory, and somebody opens the front gate and all of a sudden what looks like a shack from the outside is actually a gigantic compound with thousands of oompa loompas scrambling to put stuff together (not saying NMA folks are oompa loompas…), and you’re standing there jaws wide open until one of them crosses in front of you wheeling a comically large cart of stuff and says to you “please get out of the way sir.” Thankfully this was me browsing Slack and the various Google docs and sheets in my room, but I remember doing that for a solid half day. Coupled with the stream of TA-related emails we were starting to get from Carsen, it was like, “oh wow, this is what it’s like.”
My immediate first thought was: “how the hell is this happening? lol oh no there’s no way this can get done.” I think that was triggered by my witnessing of the emergency of that day (there were usually several a day), which was the realization that all NMA material had to be copyright-infringement free, so teams were rallying the content creators to remake their figures and/or get permission from journals so they can use figures as is in the lecture slides. I was literally remaking one panel of a figure for a paper submission that week and I spent a good hour fuming about it. Now we’re asking these faculties to redo their figures for a free summer school lecture, some of which look so old I’m sure they were originally printed in black and white? Major lol.
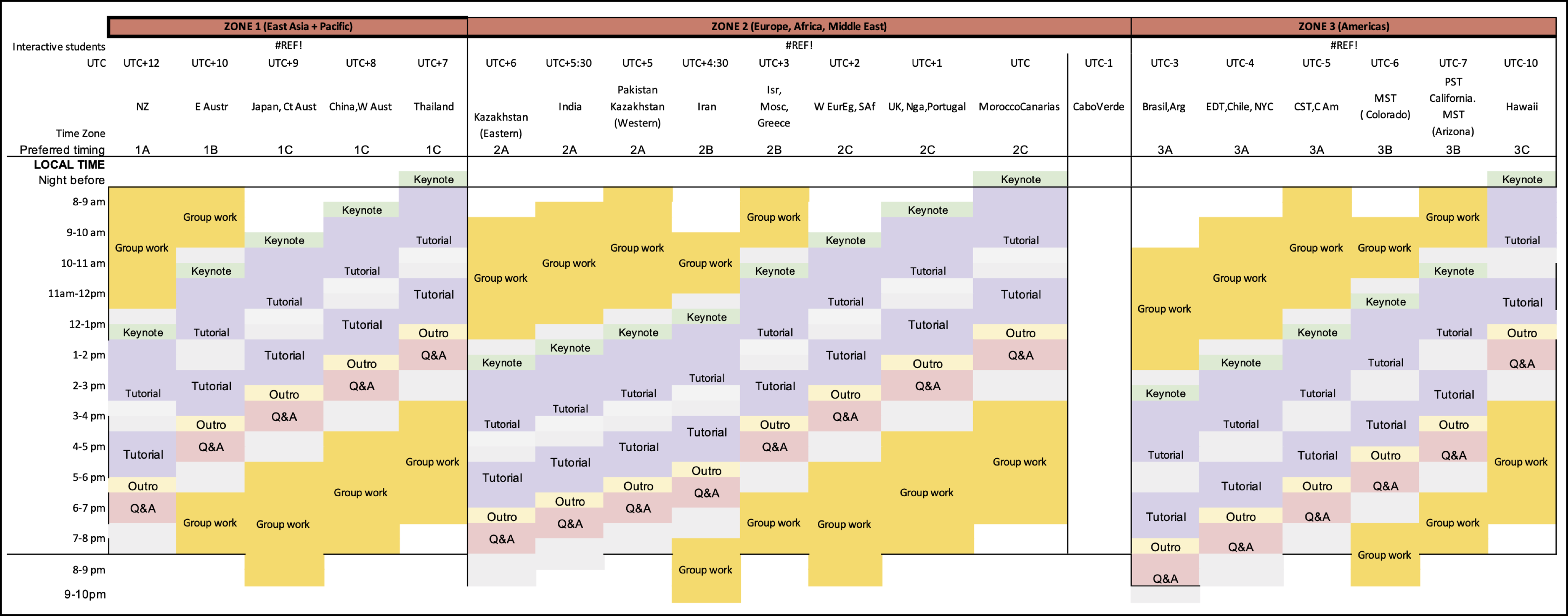
The second thought I had was: “hold on, I know of most of these people, either IRL, on Twitter, or I’ve read their papers. These people…all have regular jobs as graduate students, postdocs, or faculties. How are they spending THIS much time on this volunteer job for a summer school… and why???” I definitely had some small fanboy moments when I saw people I did know, and even the people I didn’t know, they seem to be high performers in whatever industry/area of research they were from, an accomplished or budding academic, across all the different teams, including the content day chiefs and the content creators themselves. Given my rant above on the institutional pressure to produce research and not waste time on teaching (much less volunteer efforts and outreach), you can see why I was a bit taken aback. Adding to that shock, TA duties were ramping up later that week, and we get this course daily schedule from Carson. I can’t imagine how long it took for the organizers to design this, and you can’t imagine how long I looked at this thing trying to figure it out. So it was all just…a lot to take in.
Back to waxing. Why did waxers exist in the first place? It’s just another example of the embodiment of the values the organization had from the top down, and I paraphrase something Michael said in one of the linked videos above: “the organizers/content creators suffer so the students don’t have to.” Here’s a quick summary of my (limited) understanding of the content creation process:
- The content day chief and content creators (CC team) decides on the topics to be covered for the day and their progression. Then slides and videos for the intro and outro lecture, as well as micro tutorial videos embedded in the Jupyter notebooks are filmed and handed over to the dedicated NMA editing & reviewing team. Videos are cut down to appropriate lengths, combined with slides (where the lecturer video is plopped into a little square in a corner of the slides), then uploaded and curated on YouTube.
- At the same time, CCs create Jupyter notebooks with code exercises and explanations in a master notebook, and the reviewing team provides feedback for tutorial organization, content difficulty, and various other high level things concerning both technical and presentation aspects of the content.
- Finally, the tutorials are handed off to the waxers to polish, which means embedding the microvideos where they are suppose to appear, making sure the notebooks adhere to the universal style guide, and that the code runs smoothly and produces the expected outputs, etc. When all that is finalized, it’s pushed from Google Colab to GitHub, where Michael Waskom’s suite of continuous integration tools generated student and instructor versions (solutions are hidden in the student versions), automatically checked for code execution, as well as PEP8 and various other custom stylistic concerns.
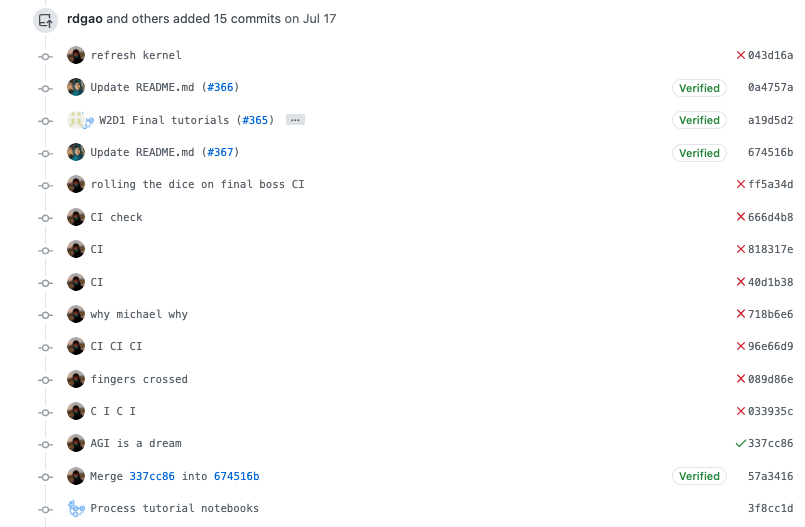
- That completes the first round of content creation, and the first version of completed NMA material is born. All of the course material then goes through “pre-pod”, where TAs pretending to be students go through the entire 3 weeks of material and provide detailed feedback regarding difficulty, clarity, and whether there is too much/too little material - basically, anything students might have issues with. That feedback is distributed to the content creators, and they modify the tutorials and reshoot some videos accordingly, pass those to the content reviewer team again for touch ups, which all have to be completed within a week. Finally, it makes it to the waxers, ready to be loaded into shipping containers for final push to GitHub, where this kind of stuff happens:
Just reading that summary feels like a lot, imagine the effort required to actually do it, both from content creation and curation’s perspective. This doesn’t even mention the “China team”, which has to figure out workarounds because Google stuff (e.g., YouTube) cannot be used in China, and I’m sure I’ve missed (or was never exposed to) a bunch of other teams that were crucial for the preparation of the material (sorry if that’s the case!). And this is only content, which is the meat of NMA for sure, but still just a component. Recruiting, logistics, sponsorship, student feedback, outreach & communications—all of these teams were needed to make this stuff come together. This also does not mention unexpected and non-school related hiccups along the way, like the “Iran Saga”, where in the span of a week, Iranian students and TAs had to be dropped because of the ongoing American sanction on Iran, and then reintegrated because NMA was granted an exception. That was definitely an emotional rollercoaster, to say the least.
All this brings me back to the same point: the team was committed, top through bottom, to making this as seamless of an experience for the students as possible. You can easily imagine a version of this virtual summer school where each day centers on a Jupyter notebook (if not a plain old problem set PDF), and embedded in it are links out to YouTube videos filmed and uploaded by the content creators themselves, with no length or stylistic consistency in any of the modalities and bugs all over, which the TAs will have to troubleshoot in real-time. Instead, we have NMA, where you get content delivered to you by the absolute experts in their respective areas of computational neuroscience and machine learning, but in a way that feels completely consistent and coherent (I won’t say seamless, but it was close).
I couldn’t have imagined an experience like this before NMA, but it dawned on me that this is how university curriculums for a single major should feel like: different classes taught by different professors, but with overarching connections and consistencies between classes. Obviously, making several college courses consistent within all possible trajectories and majors they feed into is a much more challenging issue, but we have millions of dollars to do it, and it’s certainly not impossible. Much of this was possible in NMA because a lot of industry-standard practices were borrowed, which is sort of ironic because universities actively borrow corporate practices on how the business should be run to generate revenue, but not how the basic product should be created and delivered to satisfy customers’ needs.
Anyway, there’s much more to say here and many details were glossed over, but I hope it conveys my impression that it was a daunting task that were pulled together by a bunch of passionate people that just wanted to get shit done (shoutout to my much more productive waxer-twin, Spiros Chavlis). This was from my notes on July 12, the day before NMA Day 1:
I’ve only been a very small cog in this machine, mostly on the TA side and helping lightly with content reviews. I’d always thought that being a small cog in a machine, like working for a large corporation, would feel really meaningless. But this has been the complete opposite experience, not sure why. The values and mission from top-down has felt personal and meaningful, and working within the local teams has been extremely smooth, probably because everyone involved has been super dedicated and competent. The waxing team from coordinators to waxers have been really good. Just impressed all around. The final products are something that everyone is proud of, and rightfully so, because the tutorial notebooks are pedagogical, and consistently beautiful across. Of course the content creators deserve a ton of credit for this, especially for following the style guides so closely while the guidelines have been fluctuating. I can only imagine the kind of work the video editing team is putting in.
As a TA: Pedagogy & Day-to-Day Execution
TAs are an integral component of NMA, and this follows from the philosophy that the school should have as much interactive experiences as possible. I’ve taken my share of online courses on Coursera and MIT OCW, and those are good if I was really interested in a topic and can go through the lectures in small bites. But NMA was not that, and if you expect students to work through 5 hours worth of coding and tutorials by themselves everyday, you’d probably…not have that many students left after 3 days, which would be a shame because so much effort was put into producing the content in the first place (it’d be interesting to see how many Observer track students actually finished all of the content, compared to interactive track students).
Like many university classes, TAs are the hands on the ground that carry out the whole operation and are the first point of contact for the students. Not only do the TAs have to be familiar enough with the content to guide their pod students and ask probing questions, they have to manage the interactions constantly, making sure everyone is contributing and engaged, as well as helping to sort out any logistics stuff. It was the explicit expectation that TAs carry the most significant portion of the teaching load, especially after the content has been finalized, and were thus treated like important members of the whole operation. To prepare us, NMA had 2 days of Lead TA training, then 3 days of TA training (which is not a lot), where Kate, Gunnar, Carsen and others went through the philosophy and logistics of the course, as well as what TA’s jobs are and how they should be performed. More importantly, we got training on pedagogical tools like formative assessments and active learning. Those first few 5-hour zoom sessions were a shock to my system for sure, but all of it was to ensure that everyone was on the same page in terms of philosophy, code of conduct, logistics, and having the appropriate “soft skill” tools to move forward, and it was completely necessary since many TAs were understandably anxious about the coming 3 weeks.
Side note (rant incoming), if you read the last paragraph and thought to yourself, “sure, that makes sense”, then you probably have not TAed for an university. As it turns out, graduate student TAs in most universities serve the exact same roles, but are more often than not treated as an afterthought. I don’t think it’s an uncommon sentiment that TAs are just the university’s henchpeople for doing all the unglamorous things, and are a begrudging necessity to keep the whole operation afloat. I suppose we should all be grateful to get a TA position that partly pays our fees and salary through grad school, depending on what your departmental support is like. But I’m not advocating for TAs to be treated like upper-class citizens around here, even though the infrastructure would crumble in less than a day if TAs went on strike (to be fair, professors are typically appreciative of the TAs work, though not always). I just think the institution should acknowledge all aspects of the job a TA has to do, and do the bare minimum to prepare people for them. Seeing how these are future professors-to-be, don’t we want to, I don’t know, make sure they 1) can teach, and 2) are happy teaching? Maybe me in first year wouldn’t have given a shit anyway, but the extent of my formal TA training was a half-day seminar in my first week of grad school, as part of the university-wide graduate student bootcamp. Not sure what I took away from it other than a boxed lunch and “don’t sleep with your students”. I think the logic is that if you’ve been a student in university, you should know how to TA. Of course, a lot of the training varies course-to-course, but most of it doesn’t. But surprising to nobody, one bullet point on a slide saying “encourage equitable classroom discussions :)” doesn’t actually provide one with the skills and tools to do that. So if you want to know how to TA better for your home institution, maybe sign up to be an NMA TA next year.
TAs also happen to be the highest-paid people during NMA, because we were the only paid people (with some minor exceptions). I genuinely don’t know what surprised me more: that every other member-including organizers, content creators/reviewers, operations and logistics team-did all that work for free, or that TAs were not expected to do the same. You can certainly make a case that TAs will get a lot out of this whole thing, like networking opportunities, teaching experience, and learning the material for free. I actually didn’t know we’d be paid when I signed up. I’m not sure what my thought process was, but I would’ve told you that there is no amount of money in the world that can pay me to Zoom-teach 5 hours a day for 15 days anyway. Now that the whole thing has ended, I am happy to report that I would have indeed done it for free, so maybe I will donate some of it—suggestions are welcome (but it’s very, very nice to get monetary compensation for that work).
So just like that, the first day of NMA was upon us. After a silly ice-breaker activity (pictured above), I cautioned my pod that it would be unwise to have expectations similar to any previous summer schools they’ve attended because, you know, the whole thing being over Zoom and all. But to be honest, by the end of the 3 weeks, it felt pretty similar to a regular summer course, if not better. Though the group drinking and sporting events, and watercooler science and networking were sorely missed. So maybe not similar, but certainly engaging, and even fun and “normal” at times. What is my metric for engagement? Number of times somebody looked like they were about to fall asleep. Am I especially bad (or good?) when it comes to falling asleep in class, maybe. But it’s rare to have a 15 day streak where nobody falls asleep, because that’s an academic accomplishment even for some faculties attending seminars (though there were definitely days where my entire group was low-energy, confused, and discouraged by the afternoon, me included). No shade on all the in-person lecture-based summer schools, but this format of predominantly interactive and small-group hands-on tutorials is almost surely more engaging than a prominent guest speaker giving a standard research talk for hours. Good research talks are not the antitheses of good lectures, they’re just not really related.
Practically, the days went something like this: as a TA, I’d prepare the night before, or sometimes (read: often) the morning of. I will watch the 30-min intro lecture, go through the tutorials to make sure that I can solve all the problems, and have some nuggets of insight in my back pocket should a relevant discussion come up. Then, everyone trickles in around 11am, say good mornings and hellos, and get on with the day. Somedays there were questions and discussions about the intro video, somedays there weren’t, but it was really nice to “show up to work” everyday for those 3 weeks and see the same people. My pod had 9 students, so I’d usually give a meandering overview of the topic for the day to the whole group, set a target for how much we should have gotten done by lunch (rarely met), and then split them up randomly into two Zoom breakout rooms. They pretty much took it from there. The NMA tutorials are all directly accessible via Google Colab, so there was no screwing around with Anaconda and local Jupyter environments, everyone just had to make their own copies in Google Drive. The groups would then go off to watch the micro-videos and read the embedded notes individually, and reconvene for the coding exercises. This was all pretty straightforward, and not much for me to report on, because I really didn’t have to do much except hop back and forth between rooms to answer questions and track progress.
The one thing that’s really worth highlighting is the advice somebody gave during the TA training (maybe Kate?), which is that students are encouraged to rotate amongst themselves on who’s “driving”. I’m not sure if that’s official NMA lingo or if I invented it for my pod, but the “driver” is the person sharing their screen on Zoom for the current coding exercise and actually typing into their notebook and running the code, while everyone else dictates for them what to type. This is a bit anxiety-inducing for everybody at first, especially for those that are not so confident about their coding abilities. But funny enough, the driver typically needs to do the least thinking (if they wished), because there are 3 other people telling them what to type, while it still keeps the driver “with it” enough to at least be syntactically correct. Once the code successfully runs, my pod was pretty good about checking each other’s understanding and making sure that everyone was on the same page, and this is where encouraging people to ask questions really become useful, even though it might slow down progress sometimes. When everyone is satisfied, they move on to the next exercise, and somebody else drives. In this way, it keeps the pack more or less at the same speed, and is just better for group cohesion in general because everybody is constantly working together. It warmed my heart when I popped into a room and somebody asked “okay who’s driving next”, and there were times that I felt bad about this, because moving at the average speed means that it’s either too fast or too slow for somebody. But as a whole, the slower folks asked incisive questions that improved understanding for everybody, be it a python syntax question or a conceptual question, and the faster folks were really good about being as didactic as possible, asking others for input and not just banging out the answer on their own. Shoutout to Sami and Yue, who were really as much of TAs as me, not just in the way they were familiar with the material, but in how they engaged the whole group to participate even if they’d known the answer.
So all that for about 2 hours, then we break for an hour for lunch, which somehow was never enough for me to actually get done eating. This really was a full-time job for 3 weeks. Same thing after lunch, where we try to finish the rest of the tutorials for the day. Whether that actually happened varied day to day. Somedays we got very close, somedays it was an absolute slog, but we’d all be totally beat by 4pm. We always reconvened for the final 10-15 minutes though to review the high-level ideas of the day, how they relate to neuroscience, and then we all added to this ever-growing monstrosity of a concept map. You can’t actually see any of the words, but I thought this mind-mapping tool (Miro) was really neat (again, at the recommendation of someone during TA training). Part of the variance was because my own expertise also varied day to day, I was pretty honest about it, and it became a fun learning process for me as well, especially to see connections I hadn’t realized before. It was like simultaneously knowing a lot of random shit I never use in my actual work, but also never being completely comfortable with a particular topic.
Lastly, it was very helpful to have a TA Slack channel where people discussed their wins and troubles, and seeing what other TAs did for their pods—above and beyond what was required—was also inspiring. I remember seeing Max’s tweet about using the Zoom poll to check for understanding the previous day’s material, and I really, really liked that. So much so that I stole it for a few days, but it didn’t last very long because it was hard to adopt a new habit halfway through. And there are so many more aspects of this summer school that’s worth mentioning, like the group projects, mentorship matching, online social activities, and yoga breaks - there just isn’t enough space for it all. Each component had its own technical and logistic issues, but that just comes with experimenting with new things (like the Mozilla Hub hahaha). I will say more about the curriculum in the next section, but I think one common complaint was that this felt more like a data science or machine learning course, than a computational neuroscience course per se. Part of it was a lack of concrete neurobiology, and part of it was (at times) a lack of clear and explicit applications to neuroscience problems, such that the psych/cog/bio people may get lost in the math, while the ML/computational people were a bit underwhelmed by the whole brain side of things. In any case, it wasn’t going to be perfect on the first try, but from my perspective, it was an overwhelmingly positive experience, and I had just an absolutely wonderful time with my pod. One day, beers on me when we see each other in real life.
As a Student: What is Computational Neuroscience?
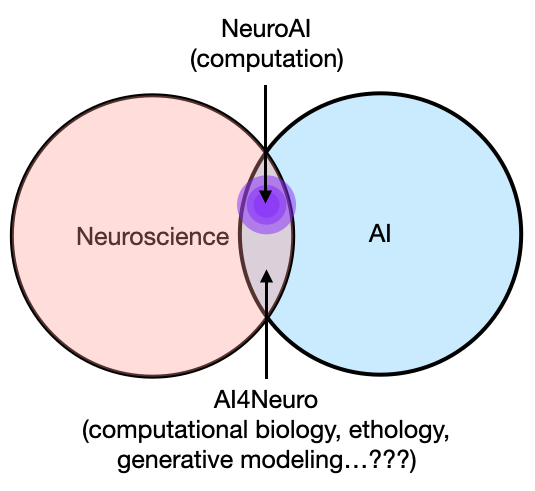
Throughout my PhD, I’ve had to grapple with what computational neuroscience means, because even though I spend 99% of my time working on the computer and having just participated in my 3rd computational neuroscience summer school in 6 years, I’ve never felt that I was a “computational neuroscientist”. The stuff I do just doesn’t fit the mold, and this is certainly true if you see the works presented at Cosyne and follow that (implicit) definition, but it’s hard to verbalize what exactly that is. Maybe it’s a function of how the NMA curriculum is clearly organized, or maybe it’s the fact that I had to actively prepare in order to TA, or maybe it’s just that after you’ve been around long enough, everything eventually sinks in. Regardless, I finally felt like I got a very coherent, high-level view of the philosophy behind (mainstream) computational neuroscience, and as a result, its assumptions and limitations. Of course, NMA in no way represents all of computational neuroscience, but its purpose is to provide an overview of the field, and from my experience, it’s pretty consistent with the major directions in the last decade. The below is not a criticism of the NMA curriculum or the field, but contextualizing what we’ve learned in those 3 weeks, and what alternatives there are to looking at behavior and the brain from a computational perspective. In brief, if there’s anything I’d add to the curriculum, it would be 1) a short but explicit primer on the history and philosophy of computational neuroscience, especially views inherited from the “cognitive revolution”, and 2) “model-free” time-series analysis techniques that many researchers rely heavily on (for those that use fMRI, EEG, LFP, etc.), but does not fit within the mold of traditional computational neuroscience (we’ll see why in a second).
On the Wikipedia page for “computational neuroscience”, it says that the term was introduced in 1985, and that its components had existed since the early 1900s with the OG integrate-and-fire model. Today, detailed biophysical modeling is almost its own niche thing, and the “lightly-biophysical” spiking neural network modeling works have largely adopted and become motivated by the same perspective: the brain is an information processing system. That statement might seem so obvious and uncontroversial that it’s hard to imagine another possibility, and while I certainly do not wish to revive the “brain is/isn’t a computer” debate on my Twitter timeline, it is interesting to note how the dominant view came to be. Probably not many people know this, I certainly didn’t until I got to work on this very esoteric project with some friends, but computational neuroscience and cognitive science are actually intimately intertwined in history, and one could argue that computational neuroscience is even a sub-field of cognitive science, or at least the offspring of neurobiology and cognitivism. You can read a personal account from George Miller himself, but he mostly focuses on cognitive science. Briefly, throughout the 60s, cognitive science was bubbling up as the interdisciplinary collaboration between a few fields to tackle the question of intelligence in the mind—computer science and neuroscience being two of them. This was spurred by technological advances as much as anything else, because computers became small enough and fast enough to do interesting things (this will be a recurring theme). In 1976, the Sloan Foundation created a Special Program in Cognitive Science, which was really tied together by this philosophy that the “mind” is an information processing device, birthed from the framework of “cognitivism” and later “computationalism” in psychology (as opposed to behavioralism). While cognitive science has somewhat evolved in the years since then (though still dominated by cognitive psychology), computational neuroscience sprinted off in this direction and, arguably, became a much more ludicrous (EDIT: I meant lucrative) research program (in terms of funding and popular appeal today, probably because, well, the brain). And because of this history, computational neuroscience and machine learning are inseparable, and it’s clear from the NMA curriculum as it reviews a series of methodologies developed in the last 30 years or so, showing that while time flows, high-level ideas are largely unchanged.
Let’s start from a very specific and straightforward example in machine learning: Generalized Linear Models (GLM). I really love this slide from Cristina Savin’s intro lecture (W1D4), because it showed how the components of GLM are “plug-and-play”, and how those components are largely irrelevant to the key idea behind all GLMs (and all of machine learning): optimization. If you plug in the identity function as your nonlinearity and the Gaussian distribution as your stochasticity (likelihood), you get linear regression. Swap those out for the logistic function and Bernoulli distributions, you get logistic regression. Critically, they can be solved by the same maximum likelihood optimization procedure, which tunes the (linear) parameters of the model to best produce the expected output given any input.
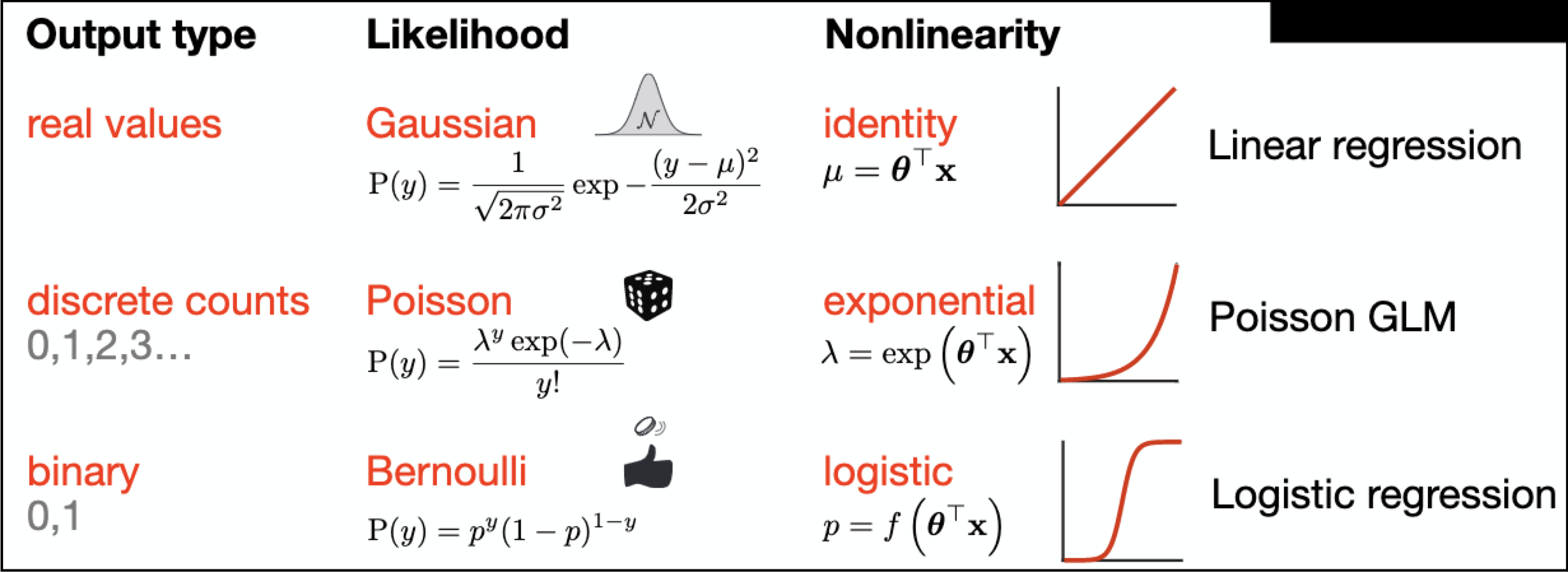
So far, all standard machine learning stuff, no neuroscience. At a higher level, you can even swap out the architecture of the model, as well as the optimization target or “cost function” (e.g., maximum likelihood vs. minimize least squares error vs. with regularization). A special case occurs when you take the exponential function as the nonlinearity, and Poisson distributions as the likelihood, which gets you the Poisson GLM. At face value, this is just another machine learning model, and can be applied to any data when the assumptions are appropriately satisfied (e.g., non-negative integer outputs). But under the hood, Poisson GLM models how single neurons encode and process information, and it has its own name in neuroscience: linear-nonlinear Poisson (LNP) cascade model. (But see the end of the post for some corrections, more technical details, and historical tidbits on the difference between Poisson GLM and LNP, very kindly provided by Jonathan Pillow, quoted from this exchange.)
For example, V1 neurons are thought to act as linear convolutional filters of the visual field (e.g., Gabor patches), the output of these linear transformations are then mapped to firing rates via the exponential function, and finally, it stochastically emits a discrete number of action potentials based on the firing rate that follows a Poisson distribution. To be technically accurate, I believe Poisson GLM is one way of solving for the parameters of a LNP model (another being spike-triggered average). The sleight-of-hand is so subtle that it’s very easy to lose the distinction: on the one hand, we have a purely machine learning model that tries to map input to output, on the other hand, we have a generative model of how single neurons behave when an animal sees a picture, and all of a sudden, they are one and the same! More importantly, the LNP neural model inherits assumptions of the Poisson GLM machine learning model, maybe the most philosophically challenging one being that when we solve for “what the neuron cares about” i.e., its parameters or filter weights, we assume it tries to do “the task” optimally. This then becomes a (rather light-weight) normative model, i.e., a computational model that solves a task optimally under the same environmental constraints the neuron (or person) is under, which we then posit to be solving the task the same way a biological neuron (or person) does, including even the internal representations.

I fucking LOVE This meme.
Poisson GLM is not a cherry-picked example, and that’s the beautifully coherent picture I got to take away from 3 weeks of NMA. Almost every single day of NMA can be cast in this form, where the machine learning model is some optimization procedure to map inputs to outputs, and the neuroscience model basically says “well that’s probably how the brain does it too.” Bayesian inference? The brain does posteriors too. PCA and dimensionality reduction? Minimize data reconstruct error, see neural subspaces and manifolds. Markov chains, dynamical systems, and control theory? Minimize future state prediction error, recurrent neural networks in the motor and cerebellar system. Reinforcement learning? Minimize action-outcome value mapping, via temporal-difference error signal of dopamine neurons. Deep learning? Well, you get the idea, hopefully. The correspondence is not only convenient, it is intuitive: optimization of the model parameters is the “learning” part of machine learning, and maybe that’s similar to how the brain learns to perform tasks? And this is why biologically plausible learning rules for deep learning is such a big deal: it would make our lives a lot easier.
In this way, I understood where the “computational” in computational neuroscience comes from: computational neuroscience is more than just using modern computational techniques, like machine learning, to help decode or otherwise analyze neuronal responses. It’s (at least in large part) using machine learning as a model of the brain (biological learning), and finding analogies between the model representation and neural representation, while attempting to understanding the computations (or, transformations) that takes place from input to output. Critically, components of the model can be (and often are) left alone as statistical or computational black boxes: it doesn’t really matter how the neuron does the linear filtering over the receptive field, and obviously V1 neurons don’t even have access to the visual field directly, but all that matters is that it “filters”. Of course, there is work being done that attempts to map the entire visual pathway to cast the operations as synaptic transformations one step at a time, but that’s more of an implementation detail than algorithmic insight. The vigilant reader will notice the use of lingo from Marr’s levels of analyses, and it’s no coincidence that David Marr was instrumental in both cognitive science and computational neuroscience, and whose distinction between computation, algorithm, and implementation translates to NMA’s very first lectures centered on “how to model”.
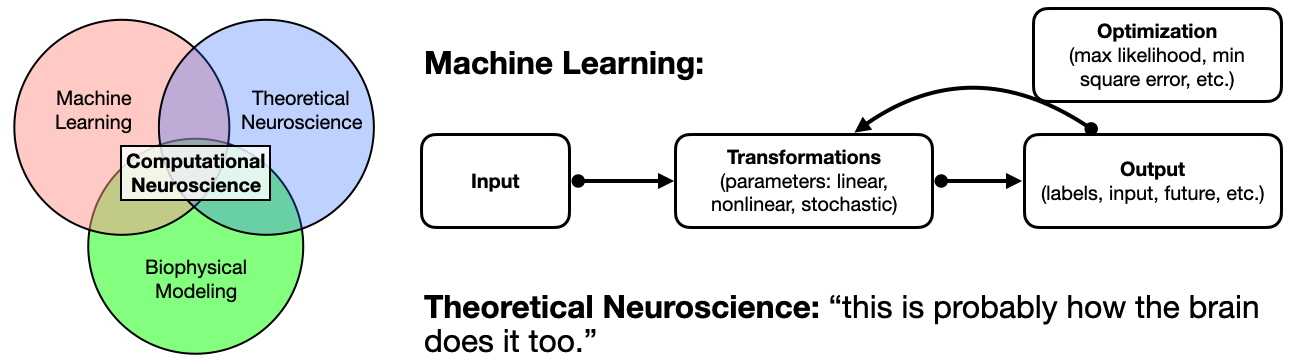
The point is, the way the NMA curriculum was organized really made me appreciate that: one, machine learning is just different optimization problems, and one can choose different probability distributions, cost functions (error in space, time, reconstruction, distributions, etc.), and make different assumptions about the data to apply different techniques. This is not to trivialize machine learning, but to hopefully ease some anxiety when an ML-outsider (like me) sees the daunting collection of seemingly disparate techniques, because there is an unifying strand. More importantly, two, “computational neuroscience” as a field truly embodies the idea that the brain really performs these computations. Why is that even a point to bring up in a blog post about computational neuroscience? Because that’s only one of many ways for tackling neuroscience using a computation-heavy approach. Spiking neural networks, for example, are not inherently about computations at all. One can mimic the dynamics of single neurons and populations using networks of LIF or more sophisticated neurons and understand a whole lot about the physiological mechanisms behind, e.g., spatiotemporal correlations in the brain. Same is true of “mass models” like a network of Wilson-Cowan neurons. But mainstream computational neuroscience further asks: what computational properties, in terms of input-output mapping, do these dynamics endow, as there are now efforts to interpret dynamical properties at both of those levels as integral for the computation in biological and artificial recurrent neural networks (e.g., computation-through-dynamics, reservoir computing).
Also, there are potential blindspots when these methodologies are not viewed within a historical context. First, as I hope is evident from that list of examples above, computational neuroscience tends to lock into the hot computational-method-du-jour. This is not inherently a bad thing at all, and to be fair, it has been a (fruitful and interesting) two-way exchange between machine learning and neuroscience. Parallel distributed processing, the grandma of deep learning, was one of the flagship products from that era of cognitivism (also closely tied to Cognitive Science, at UCSD, no less) that took ideas from neuroscience into computer science. The danger is just that trends happen, and typically, the same trend happens again in 30 or so years. GLM might be hot again in 10-20 years, who knows. There’s been enough written on both sides of this debate (which, funny enough, came up multiple times in my pod), and I’m not committed to either position very strongly, but there is some naivety in thinking that XYZ == the brain without acknowledging that we thought that for pretty much every new XYZ. I suppose you could argue that they are all in fact the same—coupled linear and nonlinear transformations—but then again, everything is dot products wrapped inside nonlinearity so that’s cheating a bit.
The other blindspot is that strongly subscribing to the computational account, and therefore focusing on methods that take machine learning models as generative models of the brain, may be incompatible with “model-free” approaches, especially in the context of a summer school. Perhaps this is just outside of the scope of NMA and speaks to a much larger divide between computational neuroscience and neuroscience-employing-computational-methods (especially cognitive neuroscience), but I think a non-trivial portion of the students came in wanting to learn more about human data-compatible techniques, some of which involve time series analysis, but certainly computational approaches that do not explicitly model the computational steps of the brain. Hell, even getting the spikes from broadband LFP recordings needs time series analysis. Again, this is not a criticism and I certainly understand the choice of topics given the timeline. Also, typing out the sentence before that, it made me realize how weird it is that computational neuroscience in part came from cognitive science, but now is as far away as one can get from the field of “cognitive neuroscience”—computational cognitive neuroscience notwithstanding.
Whoa, that got kind of long. Well, these are my thoughts from this whole experience, which has been incredibly rewarding and a definite highlight in this dumpster fire year of 2020. I could not recommend it more to people, either as a TA, student, volunteer, or mentor (or all of the above), and at the rate that this team iterates to improve, I’m sure NMA2021 will be even better.
EDIT: details on pGLM and LNP. JP: “One quick note on GLM vs the LNP model. (I agree the differences are subtle, but there are a few key diffs!) 1) GLM assumes a fixed nonlinearity (eg exponential, sigmoid), whereas fitting the LNP model generally involves fitting the nonlinearity. (Technically, if you fit the nonlinearity along with the filter, you wouldn’t call it a GLM!). 2) The nonlinearity in GLM must be monotonic, whereas LNP nonlinearity can have arbitrary shape (eg quadratic). 3) LNP model can have multiple filters, whose outputs are combined nonlinearly (i.e. via a multi-dimensional nonlinearity), whereas GLM uses a single linear projection of the input. NB: the “maximally informative dimensions” (MID) estimator proposed by Sharpee et al 2004 is simply a maximum-likelihood estimator for the LNP model (albeit framed in terms of information instead of log-likelihood) ref (…) Although one additional complication is that with Poisson GLMs, it’s common to use spike history as input… which makes the resulting spike trains non-Poisson. Generally people don’t (for whatever reason) do this with LNP models. As a result, pGLM models can capture non-Poisson spiking statistics, whereas (standard) LNP models can’t. When I was working on these models during my PhD, Eero Simoncelli wanted to call pGLM with spike-history the “recurrent LNP” model, which I think is nice, but Liam won out and (following Wilson Truccolo & Emery Brown) we stuck with GLM.”
RIP.