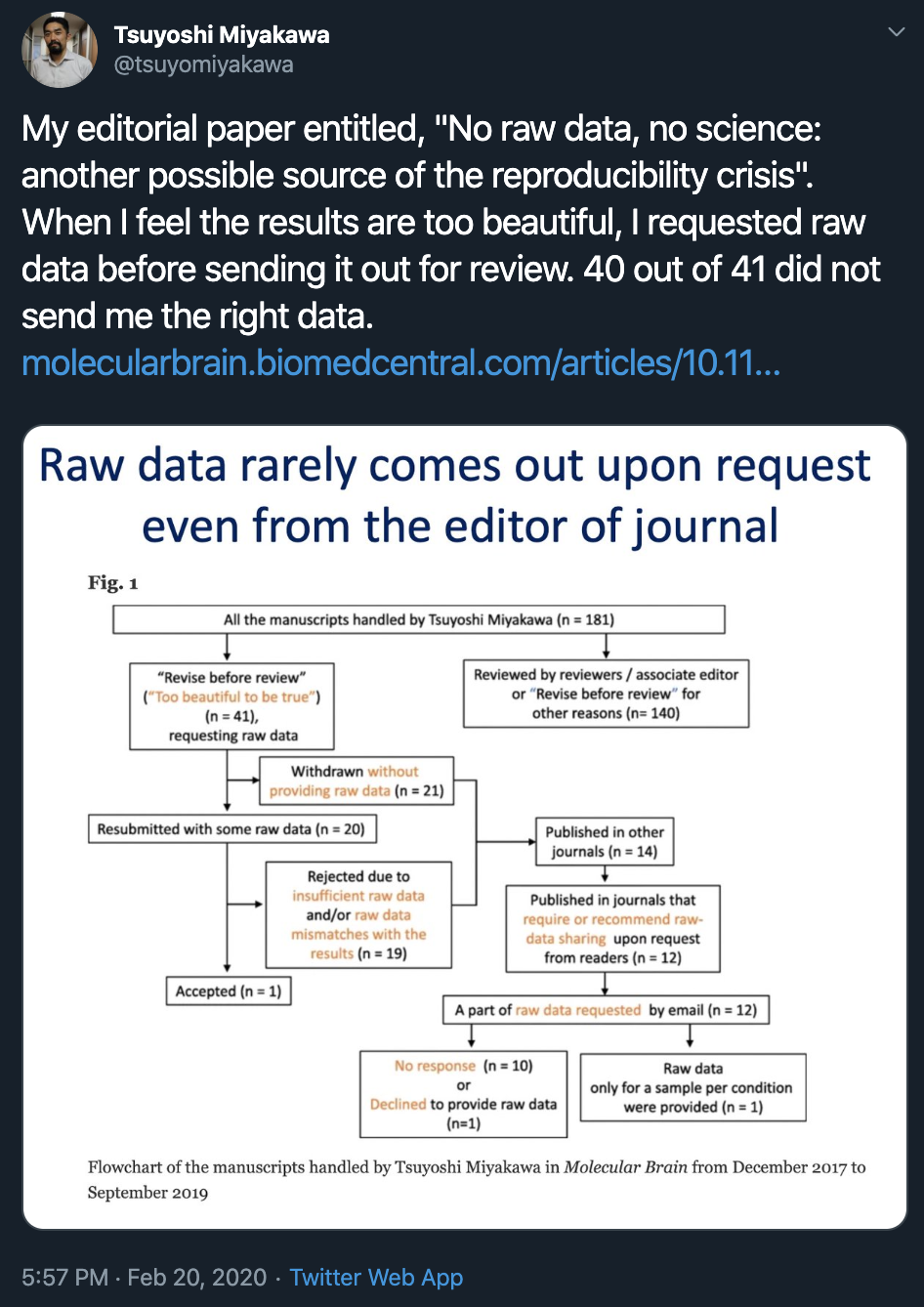
I saw this tweet and like every reasonable human being wanting the best for our body of scientific knowledge, I was deeply horrified. But as a PhD student in the thick of science for 5 years, ultimately I was unsurprised. And perhaps a little disappointed that I was unsurprised.
Then I thought, “wait, if I had actually collected data for my experiments, and an editor, or worse, some random grad student asked me for it, be it pre or post publication, how would I respond?”
Probably something along the lines of “uh yeah I’d love to mam/sir but I’m juggling a million things right now and I will get back to you shortly but probably never. Unless you’re nominating me for some award, or the paper’s acceptance is contingent on me handing over this data, then I will hand deliver that data to your door in whatever standardized format you want, even if it’s on a stone tablet.”
I have a hypothesis that (most) people don’t make their data available not because they are trying to hide or hoard it, but because (most) people are just lazy and have too much other shit to do in their lives. Okay, I’m sure some people really do actively fudge data, or are intentionally hoarding nationally funded resources for their own career gains, even after they’ve signed multiple documents declaring the availability of that data. However, I’m choosing to believe that most scientists are not that petty, and are in this profession for some grander ideal of the pursuit of truth. As a result, most people, especially really busy and overburdened grad student (literally, this week I learned I was rent-burdened???) just don’t have the capacity or motivation to deal with some shit that makes literally no impact on their lives. Honestly, if I was polled with one of those email surveys asking me to hand over my (imaginary) data, I might be like “nah, I’m good, I am shameless enough to be included in that “no response” group…unless you’re calling out all the publications that don’t hand over data.”
(Jokes on you I don’t have any data.)
Why do I say that? We might think that people would only refuse to submit data if they knew something was wrong with it, or want to hoard it for themselves. Those are definitely valid reasons, but not the only ones. I think people would also not care enough to submit their data if they think there was absolutely nothing wrong with it. Why waste their time giving it to a third party to re-analyze, especially if all that will accomplish is having some random person emailing you every 3 days asking you about every tiny detail about the data and your code, only to result in the same conclusion? Great. I’ll spend 4 more weeks on this beast of a project and get nothing out of it. Literally nothing.
The road to shaky scientific foundation is paved with guilt, fragile egos, but also hubris and pure, unadulterated, laziness.
Here’s a different question: if something actually important depended on my data or analysis, would I try to be damn sure that I didn’t screw something up? Probably. Like if whatever discovery I found was going to be used in clinical treatment, I should be pretty damn sure nobody’s going to die from some stupid oversight on my part. That’s the difference between science and engineering. In engineering, if you fuck up, somebody might die, or lose a bunch of money, or at least be really, really unhappy with you in a direct way. If you do that in science? Nothing really happens, I guess, because it doesn’t really matter…
…except when it does. It does matter when your fantastic finding is now trying to be reproduced by labs all over the world and millions of dollars worth of grant money are poured into a line of work all because your data or analysis was shoddy, or at the very least contain some non-trivial (albeit non-intentional) errors. And this only happens after some of those dollars were already burnt in trying to reproduce your findings. The more stellar your finding is, the more people there are that will try to reproduce and build on it, and for longer will they try to do so, because they really, really want to believe your result. There’s a pretty famous anecdote about Millikan’s oil drop experiment to determine the charge density of an electron that’s basically a perfect example of this (the persistence, not the fudging).
Science is self-correcting, but unfortunately you’ve just fucked over 2 dozen grad students and their fragile self-confidence. That emotional scar of trying to reproduce something that’s so obviously true but failing like you couldn’t add 2 + 2 will sting for a while, and very rarely do you have the fortune of somebody else working out at the same time that you were actually right, and the incumbent results were wrong. The first time I heard someone share that sentiment, I was like, “what? I would just assume the person who collected or analyzed the original data fucked it up, and call it a day and move on with my life.” Code and computational models? Sure, takes a few weeks, maybe months if you are really boneheaded. Wetlab or animal experiments? Your whole PhD, maybe. Even if it doesn’t literally take your entire PhD, wasting 2 years failing to reproduce something has effectively snipped your scientific career in the bud, or at least gave it a strong kick in the balls (and whatever the lady-equivalent is) because imagine showing up to grad school and they put you in the same cohort as the third years and expect from you things such as advancement and thesis proposals.
Anyway, clearly I’m very invested in this as a graduate student. But the more damaging consequence, obviously, is for science as a whole. Yeah, the people are the science, but I mean, the grad student will still carry on with their lives (hopefully), but science will take decades to recover from one faulty but really “well-known fact”. And the public? Who even knows how long that recovery takes, if ever? I mean, there are probably people that still think phrenology and psychotherapy are scientific disciplines. Forget those, there are STILL otherwise perfectly reasonable people who don’t vaccinate their children??? Needless to say, it’s damaging.
So, to summarize:
-
On the one hand, I collect some data and write a paper that might never become well-known or go viral. I have no incentive to really invest work into making my data and analysis watertight, even though I already think they are.
-
On the other hand, maybe my paper will blow up, and a mistake will fuck over a big lot of my fellowship and waste tax money my parents put in just because I was an idiot somewhere in my protocol (again, assuming I was just lazy and/or careless, not willfully negligent).
Seems to me like there’s a pretty obvious solution then: forget uploading your data when you publish, because there is a very high likelihood that it will not blow up and impact the future trajectory of, well, anything. Sure, it’s still incremental evidence, but it will not alter fields of research.
But, you should sign and swear on your mother that were it to reach some critical citation count per unit time, and that there’s a high likelihood that it WILL blow up and become science-viral soon afterwards, you must release the data (preferably in some reasonable format) at that time, such that at least somebody can now check over your work before 10x more people follow suit on some erroneous idea. That threshold can be determined based on some viral coefficient, I guess. We should probably have just as much panic and internal doubt when a piece of science finding takes off at the rate that the corona virus is taking off. Scientific skepticism knows no bounds during reviews, and steadily drops to none as more people buy into an idea. Maybe we’re not so different from your regular Jane and Joe.
(Actually, that’s probably a smart practice in general: when a foundational/seminal piece of work is about to hit like 1000 citations, it’s worth spending money trying to reproduce explicitly it in an independent lab, instead of many labs trying to and failing to reproduce it under the table and that becoming an implicit but hidden knowledge in the field. The NIH should have an arm to fund that, like a pot of bounty money that it hands out with no strings attached if a group agrees to take on reproduction of said result within the next 3 years or whatever. Science bounty hunter. I like it.)
How will that play out? Well, now I gotta make the decision when I submit my paper: if I think this paper will be pretty mildly received, then I don’t really bother. But if I think a paper will take off, then I’ll probably make sure ahead of time that I would be able to hand over that data, or at least know how to get it to that stage. At which point I’d probably just do it now because future Richard is going to be very fucking upset if amidst the celebration of his 1000-citation paper, he now has to go home and fulfill this stupid contract and hand over data from 10 years ago, which probably lives on a device that his shiny new MacBook ProProXII 18 doesn’t have the connector port for anymore. Worse yet, he might have to collect from a thing that’s the modern equivalent of a tape recorder or floppy drive. Where the holy hell am I going to get a floppy drive reader?
The accidental byproduct is that it plays on the ego of the brasher of us who thinks everything they touch is gold (and is presumably more likely to make an innocent mistake), or maybe even the hope (i.e. delusion) that their paper WILL blow up. And for those that don’t have such fantasies, at least there is a mechanism to really check when the need arises.
I think this is also an amicable solution for those that live in palpable fear of data parasites. You have some hot off the press Neuropixel or ECoG data? Fine, keep it. Keep pumping them papers if you think it will be that dope. Then when it does reach the viral threshold, there will probably be enough groups trying to reproduce what you were doing, that it’d look favorably on you to share that data (let’s say 1 group per 10 citations in ML, 1 in 25 in biology. I don’t know, I’m just making up numbers).
But you might say that’s an imperfect solution, because all data should be shared, and upon first request. Yeah, I agree. I think people should have universal healthcare, too. Now go do it. I’ll wait.
The point is, this might not move open science forward by much, or it might even hinder it such that current sharers are now incentivized to also abide by the threshold system, though I doubt it since they are really nice people to share their data in this current situation. No, but it might fix actual science, so that years of work are not built on shaky foundations. And isn’t the point of open science to fix actual science, anyway? The secondary outcome is that this will hopefully encourage enough of the lazy and apathetic people to share their code and data such that it would now be weird to not sign and uphold the contract to share them upon achieving viral status, at which point the only reasonable conclusion is that you don’t share because there’s something weird about your data and you know it.
Honestly, re: the flow chart above, I’m still incredulous that there are people who submit a paper and then retract that submission without saying anything at the first moment when their data is challenged. What the hell are these people doing???
Also, the premise for this concept working touches on the fact that the value of publications are over-inflated now, such that most single papers don’t really matter all that much. For every single paper that concretely contributed to the field, be it through data or code, those raw resources should be just as important in upholding the findings as the findings themselves. But that discussion is for another day. Naively, though, I think uploading data or code for open source use is the surest way to get citations without a paper that actually blows up on grounds of scientific discovery.
Anyway, that’s my half-assed solution. Of course, I’m mostly joking. Please make your code and data available ASAP. My personal threshold is if somebody asked me in a personal communication to use that data or code for actual scientific reasons, because I just cannot stand the shame and I’m not confident enough that I did everything right. Your mileage may vary, but do so at some reasonable threshold, please.