“…I’m hoping for there to be a similar community for creating, curating, and contributing to a body of research that uses ML and AI to advance our understanding of neuroscience, neurobiology, and neurological disorders.” Me, January, 2024
Okay I’m gonna be real here, back when I first started writing this “series” in 2024, it was mostly to rant about yet another rebranding of “computational neuroscience” that’s focused on a theory of intelligence centered on computation, and again one with little room for methodological research in service of all the other (arguably bigger) branches of neuroscience. I also didn’t think #AI4Neuro would actually become a thing, nor that I would at some point have to seriously write about what I thought it was or should be. That was future-Richard’s problem.
Well past-Richard is a dick (ha ha), especially since now-Richard is supposedly building a group today that plans to do “AI4Neuro” research. So I figured it might be time to think hard about this, if for nobody else but myself, to have some intelligible framework to guide our work.
As prescient as I was, it turns out I have even less time for composing internet rants. Time flies and it’s been a very interesting 2.5 years (!!) witnessing the explosion of AI4Science as a whole, and now, AI4Neuro. So much so that this particular topic required multiple workshops across the world this year, and several related ones at NeurIPS alone, and even more already planned for 2026.
So, for once, I can be less grumpy, and write a weirdly positive and constructive blog post.
Again, big disclaimer: these are my personal opinions unless I’ve inadvertently regurgitated something insightful that’s already been said, and do not represent 1) those of my current or past employers, 2) any member of the community, nor 3) a comprehensive scientific review. On that last point, like most AI research, there are way too many things happening way too quickly, and if I don’t cite something, it’s because I’m ignorant and it didn’t pop up in my various feeds in the last 2 months—you can either drag me on social media or submit a PR on GitHub.
Foundations: the long and short of it.
aka, too long; didn’t read:
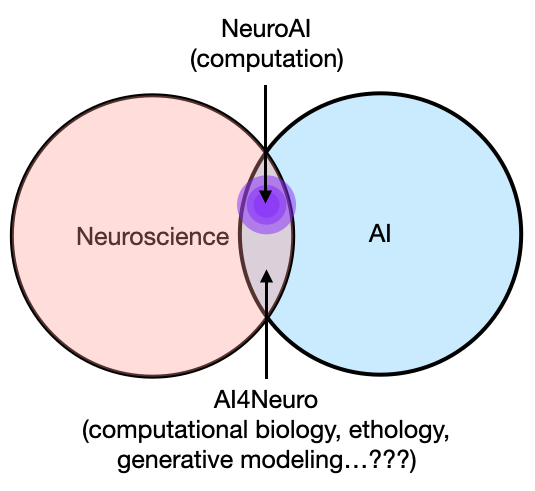
If #NeuroAI is about using AI as a model of biological computation and intelligence with the synergistic goal of building better AI inspired by the brain, then #AI4Neuro is about using AI as a tool to help neuroscience research, even (and especially) those unconcerned with “intelligence” per se.
In short, this finale of the AI/Neuro manifesto has three main premises:
-
AI4Neuro is methodological research: meaning, not only using AI, but developing, understanding, documenting, and educating about the use of AI methods for various aspects of neuroscience research, potentially beyond its application in data analysis and theory / modeling.
-
AI is unlikely going to discover something fundamentally new about the brain: with the exception that exponential continuous progress at some point starts to look like (or enable) a discontinuous, qualitative change in paradigm.
-
AI can and will accelerate neuroscience research: the more productive question, at least on the timescale of the next 5-10 years, is how to use AI in interesting and clever ways to help us do neuroscience better, faster, and cheaper. We can do this without burning a hole in the ozone layer or through our pockets.
But the most important point is this:
The fundamental principle of using AI, as is the case with any technology, is that it enables us to do some tasks extremely efficiently. The catch is, however, that it usually requires an “oracle” or verifier (or verification process). To fully take advantage of AI, we need equally efficient and trusted verifiers to drastically minimize (or replace) human-in-the-loop. I’m of the opinion that we simply don’t know enough about the brain at this point to establish or use trusted algorithmic verifiers on the science. This is why we are going to suck at using AI for neuroscience to its fullest capacity at first, especially compared to other scientific fields like physics and chemistry—but this is where the exciting opportunities lie ahead.
In other words, don’t let AI do your homework without having the ability to check over it yourself. This is true no matter how you use AI, through the chat interface for your literal homework or through agentic LLMs on your research paper. Later on, we’ll look at what “checking our answers”—verifiers—can mean in this context.
If you want to skip the interpretability discussion of deep learning and go straight to the meat of why AI will suck for neuroscience, you can jump to this section.
If you have a good grasp of classical vs. modern AI, and want to skip the build-up altogether and just see some very interesting exceptions with shared design patterns right away, you can jump to the last section.
If you want a hot (and perhaps sobering) take, go right to the end.
With all that said, let’s dive in…
What is AI4Neuro AI, for Neuroscientists?
Depending on who’s reading this and what kind of media you consume, “AI” can be anything ranging from ChatGPT, our formless Savior of Humanity, the Terminator, or linear regression. When I first sat down to write this, I realized I don’t even know what “AI4Neuro” actually means, and a large part of that is because it’s hard to nail down what “AI” means today.
There are certainly instances of things that unquestionably fall into the bucket of AI4Neuro, like GPT-style foundation models of brain data and using LLM agents for research. I can’t say why I think that, but they smelled right. But it’s hard to come up with principles to guide our thinking about the subject by looking at individual examples alone.
At the same time, it’s maybe too ambitious to come up with a general definition of AI, and I’m certainly not qualified to do that. But in the realm of things that neuroscience and neuroscientists are concerned with, I think there is a definition that can be useful to guide our adoption of AI in advancing brain research. When I ask myself this question, the first answer I came up with is this:
When I say “AI”, >95% of the time I actually mean machine learning (ML), but I decide to use AI instead for marketing / recruiting / asking for money.
For whatever reason, AI is the term that took off in the public consciousness, not ML, and so when talking to a potential funder, generalist reviewer, or student, they might not appreciate what “ML” means relative to AI, but they certainly are looking for “AI”, because that was in the news or funding call. I feel a little dirty every time I do it, but it’s sorta like simplifying your research for a lay audience, I suppose. I’m including this because it’s only a half-joke, since there is a very real hype / bubble around AI that we can honestly acknowledge (and take advantage of, if you’re morally flexible).
Okay—honest, but not very useful.
I should mention that some people are of the opinion that ML is a subset of AI, and some think the opposite. Without getting too deep into semantics, there are actually some key differences between the two. In particular, “AI” suffers from some issues that we should be aware of that ML (defined by, for example, the contents of the Bishop book) does not, or at least not universally. It’s precisely these issues that should inform how we think about, use, and improve the adoption of AI in neuroscience, and in scientific research in general.
So, what is AI, for a neuroscientist?
For me, a useful working definition in 2026 really boils down to data-constrained artificial neural networks assisted by dedicated accelerator hardware and software.
So deep learning, basically, and everything it enables. But the important properties are that “AI” (1) approximates functions using flexible and expressive modules (i.e., various neural network layers), (2) is learned from training data, and (3) through efficiently optimizing an objective or loss function.
Below, by the way, is Wikipedia’s definition, which references the classical AI-as-human-intelligence (GOFAI-y) ideas in the first paragraph, then lists full-fledged modern “AI” applications in the second.

I don’t adopt either definition here because for a (neuro)scientist developing and using AI in their research, direct application of LLMs still only represents a subset, and it’s more useful to think about the components powering those applications. In 2026, that is mostly deep learning and GPUs.
“wow thanks dude, you wrote 3 blog posts just to bring us back to 2012 and tell us about deep learning?”
Yes, but a better question to ask is, why is this the right cut-off for “AI” in AI4Neuro?
We don’t know what we’re doing anymore.
To illustrate why, it’s useful to think about “pre-AI” days of computational neuroscience, by which I again mean the broader one—not only neural computation, but developing and using computational tools in general:
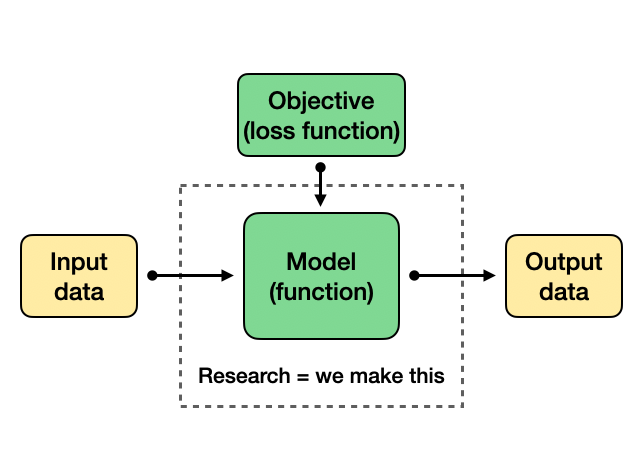
Whether you’re doing data analysis or modeling, neuroscience research on a computer almost surely means you are interested in building some kind of transformation or function, which we can abstract away as a box that processes input data and produces output data.
The input / output could be neural data, behavioral data, experimental stimuli, whatever. Basically, in goes some stuff, out comes some better stuff, and the actual research work often is to design the box and/or make it better at doing what we want it to do, defined by a task around the input and output data. This could mean better prediction accuracy, or providing a better match to how the brain does something.
By and large, for such a box in the pre-AI days, (1) we knew exactly what the function is supposed to be and what it’s supposed to do, (2) it “works the same way” no matter what data it sees, and (3) we know exactly how to (re)make the box. Phrased more technically, you might call them analytical—or at least interpretable—transformations or forward mapping, data-dependence, and inference procedure. Having this understanding about our algorithms guides our thinking and implicitly provides safeguards when using them for scientific research.
As a trivial example, the Fourier Transform and digital filters work the same way and are derived the same way no matter what data you apply them on. The recipe for getting the coefficients from data is fixed, and so is what the transformation does, i.e., the forward mapping is analytically defined. The method development component of research then involves designing better algorithms and settings by, e.g., stacking multiple such transformations, but in a way where we always knew what’s going on.
Take PCA and linear regression as slightly less trivial examples: yes, the resulting weights and components are data-dependent, but given a dataset, we know exactly how to get there, and we are fairly comfortable with our description of “what they do”, i.e., linear projections optimizing for a specific objective. In fact, optimizing for a different objective (e.g., L1) gets you an entirely different name and model inference procedure.
The line starts to blur slightly when hyperparameters and complex inference procedures are involved, like in regularized regression, because the eventual hyperparameters (and therefore model) is optimally chosen based on cross-validation data. But even in those cases, how the box functions and how it’s constructed doesn’t fundamentally depend on those hyperparameters or data. The transformations are the same, only the specific “amount” changes. Gaussian mixture models are another good example of this, where finding a good transformation that maps from data to clusters (i.e., the inference procedure) is fairly involved, but the function itself is well-defined and interpretable—they’re Gaussians sitting on top of your data.
This, by the way, is part of the reason why I made a distinction between machine learning and deep learning / AI: in many “classical” statistical ML models, much of the work was somebody painstakingly designing an interpretable (forward) model / transformation and the corresponding inference / model-fitting algorithm (one of my favorite examples here), for a given objective function (e.g., maximum likelihood). Yes, the process of finding the best-fitting model given the dataset is empirical and often stochastic, but the model itself and the formula to get there tend not to be black boxes.
Admittedly, the line is blurry, especially as we move towards flexible functions and “general purpose” inference procedures. Stochastic gradient descent is a clear example of this: jiggle the parameters towards the direction in which the loss improves. We can (and do) apply this to optimize many classes of transformations, but I would argue that deep neural networks stands alone, given the massive discrepancy between its components and the eventual, whole transformation—especially when data-dependence or “gating” is introduced.
To summarize, aside from the data, the ingredients we have are: the intended transformation (what is it supposed to do), the objective (when is it doing a good job), and the inference procedure (how to find a good transformation). The product or “artifact” we care about is typically only the eventual function / transformation itself, like the filter coefficients, regression weights, or model parameters.
For scientific research, it’s usually good if we understood these ingredients well, where the function is “the box” and what we spend the most time thinking about, so that we can in turn use them to analyze and interpret the brain data we don’t understand. As exemplified above, pre-AI artifacts in computational neuroscience rarely violated this assumption of understanding for all 3 components simultaneously. An individual person using a function might not understand everything, but somebody did.
But now, anyone anywhere with a GPU can essentially create a completely new transformation from scratch—a named function that in the 1800s could have given them nerd immortality—and nobody on this planet would be able to tell you what the thing actually does anymore.
“I laugh in the face of danger.”
Hopefully now it’s clear why I settled on deep learning as the boundary between pre-AI and AI.
Again, “AI” here is (or uses) deep learning to approximate an unknown and often ill-defined transformation, by optimizing for a general and interchangeable objective function that sometimes has very little to do with the specific problem (MSE, cross-entropy, etc.), on a particular dataset of finite size and using stochastic optimization algorithms.
In other words, it flaunts its disregard for these requirements of “understanding”, and laughs in the face of danger. In fact, you could almost define “AI” as any artifact for which we don't know exactly what it does, nor how exactly we arrived at it.

What AI offers is powered precisely by its violation of the “need to know”, enabled by the flexibility and a lack of specifications unless absolutely necessary. In fact, a tenet of modern AI is to have as few “inductive biases” as possible and just let data shape the very flexible function approximator (aka Transformer lol). This flexibility, coupled with clever ways of representing (e.g., tokenizing) your data as input to the network—and of course, a shitload of data and GPUs—resulted in not only powerful language models, but really interesting multi-purpose and context-sensitive models that can deal with messy, heterogeneous brain data.
But the difference is that, after crafting such a flexibly tailored transformation, you produce an artifact that is in principle a function like before, but now one that has been irrevocably embedded into it the decisions surrounding idiosyncratic data, loss function, and hyperparameters.
This presents a fundamentally different picture, where now “the box” contains not only the function we wanted to design, but everything else in the workflow. The worst part is, not only do we not know the other stuff that’s in the box, we don’t even really know what the function itself “does”.
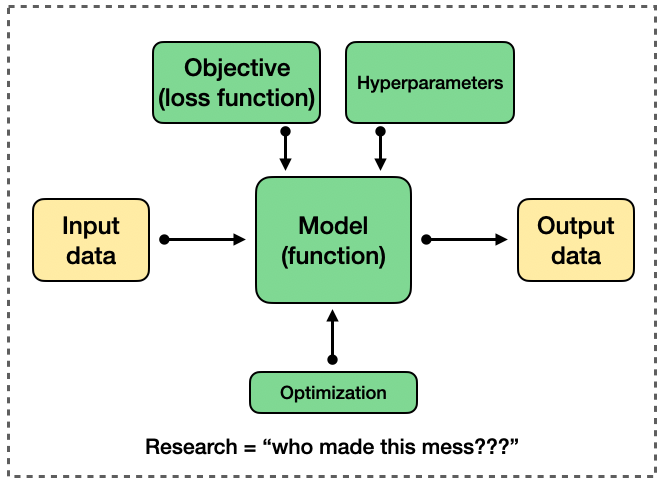
To be very clear, this is not some groundbreaking insight I personally have about AI or deep learning. There have always been communities that worked on theoretical understanding and interpretability of deep learning (e.g., Andrew Saxe, Andrew Gordon Wilson, some non-Andrews too…), as well as more “defensively” framed topics like robustness, safety, and fairness.
Of course, a solid theoretical understanding goes hand in hand with improving the methods in a principled way so we should definitely aspire to it. It’s just that these topics became sort of niche silos in the context of “mainstream” AI research where one could get away without considering anything other than raw predictive performance. This is often a (valid) criticism of the thousands of papers trying to make a 0.XXX% gain on a benchmark table, but doesn’t necessarily need to be:
Since deep learning in the end involves an engineered system towards fundamentally application-driven goals, it’s okay if the box just works without bothering too much about “understanding”, assuming that it doesn’t accidentally or by design do something racist, drive a car off a cliff, or kill a bunch of people (which, to be clear, are all things that have happened).
Science needs tools it can trust.
But this is not the case for scientific research, especially neuroscience, because…well, understanding is unfortunately kinda the whole point.
And I’m resurfacing these old insights and concerns because while many in ML have been grappling with and making these issues known against the tide of “standard” AI research (remember when a Stochastic Parrot tried to slow a GPU-powered tank column? THAT was prescient), they are not necessarily in the minds of neuroscientists trying to use AI for their research, but probably should be.
Actually, scratch that. Don’t just keep these “peripheral” issues—interpretability, robustness, safety, understanding—in mind. These research directions are central to the usage of AI in scientific research, and neuroscience in particular. It’s actually the whole thing. AI4Science as a research field, in some ways, should be synonymous with these concepts.
Speaking of “peripheral” issues, there are a lot. A recent perspective nicely outlined many of the sociological challenges for AI4Science to overcome, especially with respect to fairness of access and recognition. Those are important concerns with widespread impact, but there are also a lot of boring, technical issues that can make AI4Science go sideways. And hence the first premise:
1. Overcoming these technical issues through methodological research, with the goal of understanding, is what AI4Neuro is!
It has been said of NeuroAI before that using neural networks as a model of how the brain works is unproductive because we’re modeling a thing we don’t understand with another thing we don’t understand.
I think the same goes for AI4Neuro too: we can’t use a tool we don’t understand to understand a thing we don’t understand.
Towards a happier marriage.
To grossly caricaturize two whole fields: AI research has the mindset of “let’s build something that works, and we can figure out why (or why not) later…in the Appendix, if there’s time”, while computational neuroscience has had the luxury of “we can trust these techniques, because we derived, understood, and built them.”
But things are a bit different when they hold hands in 2026, and if you now simply put these two attitudes together as the ~intersection of AI and neuroscience~ and rely on good vibes, it’s a slow disaster waiting to happen…or silently burn a hole through the ozone layer for no good reason. We cannot by default adopt the mindset of “let’s iterate through the configs until we find something that works”, or at least not as the primary goal and certainly not the only goal.
Instead, methodological research now not only includes building new tools and techniques, but also in characterizing and understanding them. No tool or method is perfect, and it’s just as important to know when and why something doesn’t work as when and why something does. In this light, treating “AI” as just another scientific tool or technique, like a microscope or a statistical test, seems appropriate.
As a researcher, you would never just start acquiring random images with a microscope without at least knowing how it works, nor do you need to be the person that built it end-to-end. But you do need to know enough about it to not misuse it. Imagine publishing data acquired from a microscope that worked as it should like 75% of the time, but nobody knew when that was.
So what are the things we need to be aware of about AI in the context of neuroscience? There are obviously a lot of situation-specific details, mostly involving the type of data you work with (images, text, time series), where and how you acquired the data, experimental configuration management and reproducibility, etc. But on a higher level, a useful mantra I’ve adopted is this:
Only use AI when you can independently verify its answer. If you can’t, figure out how.
It’s pretty simple actually, and again, it’s like any other tool. I didn’t invent this. This is the operating principle for how a lot of people—correctly, I’d argue—use ChatGPT / Gemini / Claude. It just so happens that it applies to the individual components, i.e., deep learning, as well, on a different resolution, and the “figure out how” part is where the novel scientific and methodological research happens.
I don’t know if this is the established technical term for it, but from here on I will call the “checking your homework” process verification, and a verifier to be the thing or person doing the verification (edit: it’s becoming the word of choice, at least in AI). It is absolutely imperative to have verifiers in the loop for any AI workflow, including and especially in science.
We never knew what we were doing in the first place.
So why are we going to suck at using AI for neuroscience?
Because, well, we don’t really know much about the brain yet to have good verifiers, beside our own two eyes.

This was pretty much the main point I wanted to convey 2 years ago, as indicated by the title that existed already then, and it hasn’t changed much: There has been a massive adoption of AI in many areas of science, you can tell by the names that pop up as NeurIPS and ICML workshops: AI4Physics, AI4Biology, AI4Materials, AI4Earth, etc. If those fields have seen successes with their usage of AI, can’t we just import their playbook and do the same in neuroscience?
I would argue no, and it’s because the application of AI in those fields can be better thought of as AI-assisted engineering, rather than “science”. The massive acceleration enabled by AI in those fields is not really “the AI” doing something super special, it’s often that it removed a key bottleneck in a workflow—the whole machinery runs as quickly as its slowest cog, and AI just replaced the slowest one.
That’s not to say that engineering is not science or is not a part of science. That’s actually precisely the point: fields with well-defined engineering problems (e.g., protein folding, material design, climate modeling) can leverage AI more effectively to solve those problems because they have a clear(er) idea of what the problem is, what a solution looks like, and how to verify that solution efficiently. In particular, many of those fields have established and trusted theories and models that can be turned into automated certified verifiers. Basically, physics-based (or, mechanistic) simulator models or important performance metrics, or both.
The difference between no AI and AI is that things run faster, often by generating potential solutions with an extreme speed-up, that’s really about it. But the whole machinery can’t run faster when one slow cog is replaced if all the cogs are slow, and very often, the critical bottleneck is not (only) that the solution-generation process is slow, but that the verifier is slow—because it’s often us, humans in the loop.
Trivial example: AI (i.e., deep learning-based computer vision models) totally could have solved radiology by now, because it’s already achieving abnormality detection accuracy matching that of human radiologists. The problem is not that it’s not good enough, it’s that it’s not 100% right and we don’t know when or why it fails, and having a human checking over the AI’s answers is functionally no faster than not having AI in the first place. In other words—and it sounds really fucking obvious, because it is—if there was an efficient verifier that was able to assess whether the AI’s answer was right or wrong at 100% accuracy, we’d be done.
Another example: AlphaFold is groundbreaking because it predicted protein shapes from amino acid sequences really well, not because it enabled something new, but by solving a problem for which we already had a solution, but now in a different and much faster way. But its abilities were really allowed to shine in the bigger context of protein biology as a field because people had various (slow) imaging modalities and physics-based molecular dynamic (MD) simulations, and more importantly, what it means to be a good solution, i.e., meaningful metrics with respect to the underlying problem. My very superficial understanding of this field now, supercharged by AI4Biology, is that all these things work in tandem to enable a much more efficient overall workflow: given blobby images from Cryo-EM, AlphaFold makes a rough guess, then MD simulations “touch up” the prediction to get a refined answer.
Now coming back to neuroscience, here’s my question: for how many problems can we confidently say that we know what we’re looking for, or that we know what a good solution looks like? I don’t mean performance on heldout samples of the same dataset the model was trained on, but more fundamentally, what problems are we even trying to solve here?
(Damn, that Ralph Wiggum meme really hits hard on multiple levels.)
Known unknowns and unknown unknowns.
I got into this business because I wanted to understand how the mind worked, was initially dissatisfied with psychological explanations, thought biology had the answer, and realized that to some extent we knew even less about the biological brain, at least with respect to the mind. Worse, the kind of questions we ask currently are much closer to “how does the brain work?” in concreteness than “what are the angles between atoms of this molecule?”.
That is to say: not very.
Of course, we can come up with contrived examples of very concrete, quantitative questions and answers, like “what is the precise firing rate of this neuron given that image?” But I think we intuitively feel that that’s not really the magic sauce to solving the brain here (not that we can predict that very well either).
If we are really being honest here, how many conceptual problems are there in neuroscience research that can truly be framed as engineering problems, and ones that can benefit from more efficient optimization or search?
I cannot think of a more perfect summary of the situation we are in than this:

And so comes the second premise: AI is unlikely going to discover something fundamentally new about the brain.
It’s not that AI can’t tell you anything you don’t already know: I didn’t know the distance between the Earth and the Sun, I ask ChatGPT, now I know. That’s a known unknown.
A more accurate statement is that AI can’t tell you anything that you don’t already have the conceptual framework to know. In other words, it can’t tell you anything you don’t know that you don’t know—unknown unknowns.
Have you ever been so confused about something (likely math or theoretical physics) that you struggle to even put into words what exactly you’re confused about, and what questions to ask your teacher to even disentangle your stew of confusion? I think we’re more or less at this point, with the difference being that there is no teacher, and we’re all equally fucking confused, including the people that make the thing (or maybe I’m the only dumb one here).
So the flip side to why AI has been (or can be) more successful in some of the other sciences is that we (unfortunately) already have good ideas and models of how things worked. In some sense, engineering problems are questions of known unknowns: we don’t know how to solve the problem in the best way, but we know there is a problem and can verbalize it precisely. But neuroscience at a high level, and perhaps philosophically (the stage we are currently in for neuroscience), is in the business of unknown unknowns.
This is a somewhat artificial distinction between engineering and science, and again, this is not at all to say that engineering is somehow “inferior” than science, not at all. In fact, we would like to turn scientific problems into engineering problems, that’s probably the best measure of progress. Perhaps theory is the better word to use here, but that doesn’t quite cut it either, because we can distill theories about very concrete problems.
Anyway, the point is that for the same reason why AI is great when you have efficient verifiers (usually based on existing theory), it’s not great when it’s dealing with unknown unknowns, because nobody—not an algorithm, not us, and certainly not the AI—even has the conceptual framework to absorb fundamentally new discoveries.
I haven’t quite decided whether “AI” as we know it today is fundamentally limited in its ability to produce unknown-unknown knowledge, or if it’s more that a human would not even be able to understand it even if it did. But the end result is the same: don’t trust any AI statements about an unknown unknown. To be fair, we do the same with human scientists, we just nod politely and say they are “ahead of their time”.
AI4Neuroscience: Reducing known unknowns more efficiently and thoroughly.
Does that mean we should pack our bags and go back to pencil and paper research until we “figured it out” about the brain?
No.
Does that mean AI will not be helpful at all in making new discoveries about the brain?
Also no.
I think it’s very plausible for AI to “make discoveries”, just not in the way we might romanticize, i.e., LLM agents working very hard and eventually coming up with a brand new theory of the brain.
For all the talks about brilliant discoveries, I think there are very few in the history of science that were truly novel conceptual advances. Those could be considered “paradigm shifts” and we very often know the names of the people that were credited with such discoveries or theories.
In reality, scientific progress is very often, and probably more so, driven by technological advances that produced tools, tools that in turn made some part of the scientific workflow much more efficient. That’s the engineer in me talking. This, I think, is one very concrete way, and potentially the only way, AI4Science can turn incremental solutions to problems of known-unknowns to a qualitative and paradigmatic shift of unknown-unknown–simply by doing things cheaper, more efficiently, and at scale.
There’s nothing really special separating unknown unknowns and known unknowns, except for the fact that we haven’t seen enough to even realize that there are unknown unknowns, things that fall outside of our conceptual model of “how things worked”. I can tell you very confidently right now that our theory of gravity is wrong, but that’s not very helpful, nor does our current theory need updating until we have seen enough to realize something feels funny. In fact, we did see some funny stuff going on out there in the universe very far away from us, using measurement devices enabled by technological advances, that necessitated crazy theories about “dark matter”.
Put more simply, and this is the third premise:
AI can help us advance science simply as a tool that enables more efficient and effective search and optimization.
We don’t really need to posit AGI or fancy “co-scientist” or whatever. We just need to think about AI as really good but sometimes unreliable search algorithms, and it’s up to us to figure out creative ways to deploy search in different data spaces and then efficiently verify. LLMs co-scientists are special not because they have consciousness, but because they have made language and any other symbolic information (like computer code) amenable to be searched, even in the “semantic space”. I find this mental model to be much more useful for myself in thinking about AI, and also figuring out which problems are good for AI and which are not (and which to avoid working on because DeepMind can do it in a day if they wanted to).
Based on that, the recipe is basically to formulate your question (and data) into a search problem, and…well, that’s about it. The recipe has one step, the rest is spending money on tokens. It sounds brute force-ish, and it is. It just needs to be cheaper and better than the standard methods using literal brute force. If you have insights about how do this for neuroscience problems—really any problem—in a clever way, I would love to talk to you.
Theory meets practice: some concrete examples and design patterns.
So that’s my grand unified meta-theory of AI4Neuro, which boils down to: “ask AI to try a lot of things and then check your homework yourself.” But does the actual research people do fit into this conceptual framework?
I would argue yes, at least the ones I like do, or I’m going to shoehorn them into it.
In this last section, I will briefly go over some clustered examples where people have come up with creative formulations of a problem that can be efficiently solved by deep learning and AI, as well as what the “verifier” looks like. Again, it’s not meant to be a comprehensive review, but a quick tour of the different flavors.
The list progresses through the years, from really “classical” deep learning all the way to our modern agentic LLM co-scientists. Hopefully you’ll see that they are connected by a common thread, and that there is more to AI4Neuro than “foundation models”. The more recent examples were haphazardly collected over the last 6 months or so, but shout out to Reilly Tilbury & Dabin Kwon (from the Harris / Carandini labs) for organizing a really fantastic and timely Cosyne workshop on “AI for Interpretable Model Discovery in Neuroscience” that really helped me to beef up my examples.
The classics
I have to start with “vanilla” supervised / unsupervised machine learning and deep learning to cover the foundations, and to expose the “default” design pattern: In classical deep learning, you’re looking for a function that takes in some input data and produces the intended output labels, which could be a supervised target (cat or dog) or unsupervised clustered identity. The search is over the space of functions that can be parameterized by differentiable deep neural networks, and solutions are optimized via stochastic gradient descent, aka follow the loss plus some random stumbling around. The verifier here, as has been the norm in ML, comes in the form of heldout test data, data you didn’t train or tune hyperparameters on. If you’re really looking for something that works instead of just publishing papers, you might even collect new data to verify.
This has been the standard playbook that describes probably 90% of deep learning in neuroscience. Applications were mostly restricted to data analysis, and it was less about (automated) discovery directly, but rather enabling human scientists to interact with their data better (like any other tool), and to make discoveries through improved data (pre)processing, visualization, etc. Think data denoising, PCA, t-SNE, etc. The other, more practical strand of applications lived in brain-computer interface (BCI) and clinical diagnostics research, sometimes even referred to as neuroengineering. “Discovery” came often in the form of “we just a made miracle”, and I personally couldn’t care less about understanding and interpretability if you can make a paraplegic person walk again.
Transfer learning: early AI4Neuro at scale
Built on deep learning, the FlyWire project and behavioral tracking tools like DeepLabCut and (S)LEAP are for me the most salient examples of “AI4Neuro that works”. Not just boutique in-house models trained on a dataset to then analyze the same dataset, but tools for neuroscientists that helped them do something out of the training distribution. The actual deep learning part, glossing over some details, is the same as in the previous section. But the real key to practical deployment here is transfer learning, especially relying on “pretrained” backbone models from the computer vision community.
All of a sudden, you didn’t need to try to wrangle CUDA kernels from scratch to harness the power of AI, you “just” need to provide some additional in-house finetuning data to make it work for your animals and lab setting (obviously out-of-the-box results can vary). So in my mind, segmentation in FlyWire and markerless tracking really leveraged AI to make doing something tedious much faster.
The hilarious thing though is that, at this point in history, the verifier basically still consisted of humans, and in the case of FlyWire, human “proofreaders” pretending that they’re playing a videogame to do manual correction on the automated output. So we are already getting a hint at the verification problem: the initial segmentation was obviously sped up tremendously by deep learning, but to actually trust those results for critical scientific conclusions, there required a verification process, which in this case was outsourced to the community at large.
Self-supervised foundation models, generative models, and representation learning
As any frontiers AI lab can attest, not only is human-proofreading-as-verification slow and expensive, having human labelers to generate labeled training data is also, and has always been, slow and expensive. Then, BERT and GPT happened: instead of training deep learning models to predict labels from text, like “is this email a spam?”, people figured out you can just predict text from text around it—no labels required.
Note: this idea existed much earlier, e.g., skip-gram and CBOW in word2vec circa 2013.
This is self-supervised learning (SSL) in a nutshell, and when you can do that really well and at scale, you get good representations of the data for free, and it generalizes to new data and tasks. Well, as much as you can have “new” data when you’ve seen all of the internet. Modern LLMs still need some labeled finetuning data, e.g., for RLHF, but at a much, much smaller scale than the unlabeled pretraining data. At some point, the propaganda machine at Stanford coined the term “Foundation Models”, and that’s what we’re going with now for these large-scale models trained via self-supervised objectives.
If there was such a thing as “the genesis of modern AI” that excludes “MORE GPUs” and Schmidhuber’s habilitation thesis, SSL may have been it. I think it’s neat that this was really enabled by research outside of model architectures and about more interesting objective functions: Closely linked to representation learning, which is arguably the primary but implicit goal, through objectives like masked or autoregressive reconstruction, generative modeling / density estimation, and contrastive / joint embedding.
Again, I want to emphasize here the critical transition in what a verifier looks like here: supervised learning requires you to pay some (human) verifier to generate labeled data, self-supervised learning has the data verifying itself.

Banger.
This is transformative for neuroscience, because we in general don’t have great labels, but we certainly can produce a shitload of data. Yes, there are certain labels we care about like disease diagnosis, and behavioral task labels have been the natural choice though obviously the brain cares about more things than arbitrary lab tasks. But from a scientific point of view, if you gave me some brain recordings and asked me to “make a function to predict X with this data that constitutes understanding the brain”, I wouldn’t know what X should be.
Turns out, taking X = autocomplete the data, SSL is the literal instantiation of “What I cannot create, I do not understand”.
So in some sense, self-supervised learning and foundation models is not only enabled by massive datasets, but by a lack of a priori defined supervised task. Following this playbook, we are now seeing a swath of such foundation models for all modalities of neural data: invasive and non-invasive electrophysiology ranging from spikes to field potentials and ECoG/EEG/MEG, structural and functional MRI, transcriptomics, whatever you can get your hands on. If you have a suitcase of hard drives filled with data, throw a Transformer and SSL at it.
People have also combined it in fun ways with pretrained vision / language foundation models to look at cross-modal representations, or if brains and language models process information similarly, crossing over to NeuroAI territory. I will also throw probabilistic generative models in this bucket, e.g., synthesizing neural signals with denoising diffusion models, which share more similarities with modern image models than language models, but the principle is in the end all the same: (conditional) density estimation.
I think these foundation models are what people mostly think of now as “AI4Neuro”, or at least a big chunk of it. If you can get good self-supervised models that are useful for all sorts of (unknown) downstream tasks more or less for free, that’s great from a practical stand point. But I think the allure is less about the downstream tasks, but more that we have a good way of doing dimensionality reduction and representation learning, with the dream that optimal data compression is ultimately an empirical form of understanding. Rejoice, if you too have commitment issues.
Addendum: Renato Duarte recently put out this very comprehensive overview—and excellent critique—of “foundation models” of the brain. It’s a great read that covers the last 10 years of papers in much more detail, and I agree very much with his reasons for why such models do not constitute “understanding”. One note is that what I consider as foundation models above is a subset of the much larger pool, one that he argues is often conflating the usage of the phrase. I agree with him there as well, both conceptually and technically. I somehow only consider self-supervise pretrained models as foundation models, though one could consider ImageNet classification-trained model as a foundation model as well since the learned representations enable many other downstream tasks. In general, definitely open waters for naming conventions and research.
Synthetic pretraining and “prior fitted networks”
Closely related to self-supervised foundation models is an even more absurd strategy: Instead of painstakingly collecting and preprocessing data from the real world, which tend to be messy and incomplete, why not just make a million times more fake data for training?
This is now sometimes referred to as Prior Fitted Networks (PFN) or simply synthetic pretraining, where “prior” refers to our prior belief about the data-generating process. Of course, this means it’s somewhat restricted by the types of data for which we have good priors (and noise models) for. In other words, data that we can counterfeit very well, either by simulating the real underlying physics (more on this in a second) or simply with statistical generative models, like graphical models and Gaussian processes. The most well-known recent examples of this are probably in the areas of:
- tabular data, where one can define all kinds of causal relationships to produce X-Y pairs of fake data (e.g., TabPFN),
- physics-based models, where we have established simulators (e.g., fluid dynamics simulations, weather / climate),
- and general-purpose time series foundation models (e.g. Chronos, Mantis, DynaMix).
This hasn’t really been done yet in the context of foundation models for neuroscience though, but I mention it here because it’s very related to the next idea. You’d think that this would never work, but it’s absurd and incredible that it does, at least in some domains. All of a sudden, we don’t even need real data anymore. So data generation is free because you just simulate as much as your heart desires, and verification for training is free through self-supervision.
But one problem persists: predictions given new data still need verification, especially for any meaningful downstream scientific interpretation. To give a concrete example, you could generate a lot of synthetic electron microscopy images and use a scheme like Segment Anything for self-supervised pretraining in a new era of FlyWire (or maybe MouseWire?). But given real new data, the automated segmentation—no matter how good the predictive model is—will still need some level of human proof-reading, especially before you can publish the connectome as a community resource that thousands of neuroscientists will use.
Inverse modeling, digital twins, and simulation-based inference (SBI) as synthetic supervised pretraining
Close to my heart, and very much related to the previous idea though with a very different goal and a literature of its own. But before we get into SBI, let’s start with the high-level problem of parameter fitting for simulator models:
In many areas of science, you have mechanistic simulator models that encode domain knowledge (or our current mechanistic understanding) of the world, often physics-based models like differential equations that describe how a neuron behaves electrically over time. This model usually has some free parameters—imagine knobs you can turn on an old machine—that represent unknown properties of the system that we’re very interested in, but don’t have measurements for, perhaps because they are very expensive or simply impossible to measure directly. For example, the concentration and movement of proteins and ions within a neuron, or the mass of a star billions of kilometers away. What you do have are measurements of other, more easily observable variables, like extracellular recordings of the neurons activity, maybe under some specific stimulation protocol, or the brightness of said star.
With such a mechanistic model, what it allows us to do in the “forward direction” is to simulate hypotheticals: given some specific combination of knob values, what does the output look like? But what we often want to do is to go the “reverse direction”, or inverse modeling: given some observed behavior like recordings of neuronal activity, find parameter values (i.e., the correct knob settings) for the simulator model that reproduces that observation.
If you can do that successfully, then you have effectively mimicked the system in a watered-down model of reality. Think shitty, low-resolution Porygon-Ditto. We can then manipulate that “digital twin” to do in silico experimentation or hypothesis-testing, and because its parameters and states represent real-world quantities, we can interpret those values as a kind of estimate of the underlying biological properties. In other words, this computer model lets you take “peeks” at the internals of your system for free.

Anytime we say “digital twin”, this graphic should pop up to emphasize how unseriously we should take ourselves. Credits to Gemini / nanobanana.
Some call this exercise parameter fitting or optimization, as in you’re looking for parameter values that optimize how closely your model simulation reproduces your target observation. If you come from statistics, maybe you prefer parameter or model inference. In more engineering contexts, this might be referred to as system identification or inverse modeling. They all mean slightly different things with different assumptions about the model and the notion of “closeness”, but the idea is the same.
How would one go about doing this? The most intuitive and dumbest possible way to solve this problem is to randomly guess a set of parameter values, generate the corresponding simulated observations, and check how closely the simulations match the actual experimental observation, and repeat until you get something you’re happy with. You can see how this becomes very expensive when you have many parameters, or if you require very precise matches to the observation. So we need more sophisticated solutions, which, to be honest, are not fundamentally too far departures from this base idea, and all center on the premise of how to take slightly more educated guesses.
In other words, it’s a search problem.
There are decades of work on methods like evolutionary algorithms or approximate Bayesian computation, and this is not the place for reviewing them. But back to AI4Neuro and simulation-based inference: modern “neural” SBI algorithms essentially use deep neural networks that are trained on a ton of simulation data to establish the inverse relationship purely in silico. A specific formulation is literally to predict the true parameters from the corresponding simulated observation, both of which we have access to because we generated them.
But the magical part is that after training on purely synthetic data, we can feed the deep neural network real experimental observations, essentially asking “what are the parameter values that would have produced this hypothetical simulation?” but without telling it that it’s actually real data. If the simulator model is very good or if we put blurry goggles on the neural network, we can essentially trick it into providing guesses for something it has not seen before.
If you slap on a fancier deep probabilistic model instead of a vanilla deterministic neural network, you arrive exactly at Neural Posterior Estimation (NPE). And if you do this search in a more targeted fashion by iteratively guessing, simulating those answers, and retraining the network, you arrive at Sequential Neural Posterior Estimation (SNPE). Then if you play around with the specific objective function and whether you predict parameters from observations or vice versa, you can essentially derive the entire family of SBI algorithms.
I obviously like this idea a lot, so much so that I moved to Germany to join Jakob’s group 5 years ago. There are now many examples of interesting applications of SBI on neuroscience problems at various spatial and temporal scales. It’s not always called SBI, nor do I think it must be, but the concept is getting more and more popular.
To end on the broader context of AI4Neuro:
Hopefully you can see how this is very related to the previous idea of synthetic pretraining. The only difference is that, instead of using a self-supervised objectives, “pretraining” here reverts back to the more classical task of supervised learning to predict parameter values from simulated observations, i.e., regression. That’s why I called this synthetic supervised pretraining. From this perspective, there are lots of interesting variations we could come up with, for example by mixing synthetic and real data or combining self-supervised and supervised objectives.
The last thing I want to point out here is that a new form of verification has entered the picture: the mechanistic simulator model. Let’s say we get from the deep neural network some predicted parameters based on an observation. The “gold standard” experimental verification would be to take those measurements to see if they match the prediction. But that’s hard, for the same reason as why we started this exercise in the first place.
However, because it’s built from our current understanding of the world, the simulator model can act as a stand-in, an in silico oracle that checks whether our predicted parameters make sense just by simulating them forward (the technical term here is posterior predictive checks). This sounds like it would be a bit circular and has to work, but it doesn’t actually. The “AI” here can spit out totally non-sensical answers, and traditionally we would have no way to know except to rely on heldout test data. But with a simulator oracle, we can at least verify that it looks like the data we tried to reproduce, which the network has never seen in training.
I’m obviously biased, but I think SBI is the first real instantiation of the fully digital search-verify-iterate design pattern. On top of that, if we cannot measure, but can somehow perturb properties of the real system, we can further check whether the same perturbation in the model produces simulated behavior that matches the experimental perturbation. Like before, you still have to collect real data, but the difference is that we have an interpretable, equation-based mechanistic model on our side in addition to a purely predictive ML model. This is the promise of hybrid digital twins of the brain.
Note: one technical point I should concede (after some lengthy discussions with Konstantine Willeke) is that “digital twins” don’t necessarily need to be mechanistic. That is to say, we don’t need to know a priori how the “twin” works by constraining its internals with reality-based equations. They could be purely “functional digital twins” or emulator models that simply mimic the input-output transformation of the real system, and parameterized by a blackbox deep neural network.
Differentiable simulators and NeuroAI
On the topic of optimizing models: SBI decouples the mechanistic simulator model from the deep learning model, where the latter is trained to invert (or optimize / find parameters for) the former by way of the standard deep learning recipe, i.e., stochastic gradient descent. In fact, AI as we know it today exists because we have spent the last 15 years hyper-optimizing the algorithms, workflow, and infrastructure of how to optimize differentiable models aka deep artificial neural networks.
So a natural question is: why not just make the mechanistic model differentiable to take advantage of those AI workflows and infrastructure?
There have been some great differentiable mechanistic models in neuroscience recently: of the fruitfly visual circuit, a JAX replacement for NEURON, and a differentiable model of the visual cortex from the Allen Institute (again, a bit biased with the first two examples). Taking the opposite philosophy of SBI, instead of decoupling the simulator and deep learning components, this idea merges the two to get the best of both worlds in one model: efficient search via backpropagation and automatic verifier in the differentiable, physics-based mechanistic model.
A softer, less integrated version of this, which I already mentioned in the context of SBI and digital twins, is to train a differentiable deep learning-based emulator model on some simulations of the non-differentiable mechanistic model, which is then much easier to work with afterwards. It’s not quite exactly the same, but conceptually, I would put AlphaFold in this category, where the deep learning model functionally replaces the high-fidelity protein folding simulator based on molecular dynamics.
I think this is an underappreciated but extremely potent facet of AI4Neuro. It’s underappreciated, potentially not even thought of as AI4Neuro, because there is no fancy AGI LLM or anything we think of as “AI” in the software sense, but just good old deep learning relying on GPUs go burrrr.

In this light, I would go so far as to say that all of NeuroAI fits into this bucket because it’s almost entirely thanks to differentiable network models that NeuroAI exists in the first place: A typical NeuroAI recipe is to train a deep feedforward or recurrent neural network on some digitized version of a behavioral task, like image recognition or decision-making, and then probing the internals of that model for mechanisms and representations similar to the real brain. In the spirit of a “functional digital twin”, it’s taken as a premise that the deep learning model is the mechanistic model of the computations involved. In that sense, I don’t think it’s controversial to say that AI infrastructure has enabled a very productive branch of computational and theoretical neuroscience, where >95% of papers following this recipe rely on pytorch / jax and GPU-accelerated optimization.
Therefore, NeuroAI is a subset of AI4Neuro. Bob’s your uncle.
Finally, to LLMs.
Abstracting away deep learning almost entirely, the last category uses what perhaps comes to mind when most people think of now as “AI”: large language models (LLMs). Using LLMs for science has certainly been the most publicized, where it feels like there’s some press release or white paper every 2 weeks about the latest and greatest version of Gemini, GPT, or Claude leading to some new scientific discovery (e.g. theoretical physics).
Below, I break it down into 3 smaller groups of ideas, all of which use pretrained LLMs in some way, but differ on the spectrum of what form of text the language model actually sees. In other words, does your LLM AI scientist only speak in code and math or actual English, or both?
LLM-assisted search for mechanistic model and equation discovery
In my opinion, this first category is the most interesting, and the one that will eventually be the recipe most AI for X-science converges to. My mental model of this design pattern is almost identical to SBI, but replacing the “vanilla” deep neural network tailored and trained for a specific mechanistic model by a general-purpose pretrained LLM that understands text.
What does that buy you? Essentially, a much larger and more flexible search space.
LLMs have seen nearly all text on the internet, which means not only does it know actual (natural) language like English and Russian, but also code and mathematical equations. Sidestepping the debate of whether they actually generalize (extrapolate), or have simply seen everything and are just interpolating within the training distribution, the observation remains: LLMs can exhibit some level of “reasoning”. Moreover, it’s better at “thinking” in some languages than others. Ask it to add some numbers in English and it fails in hilarious ways (though this is getting patched), but if you allow it to use tools by writing and executing programs in the language of computer code, it does much better. To be fair, humans are not so different.
It just so happens that most areas of physics sciences and engineering work either with models and equations that can be turned into computer code (e.g., theoretical physics, computational biology and neuroscience, mechanical engineering), or simply computer code itself as the object of interest (e.g., computer science and software engineering). We already discussed the use of mechanistic simulator models that are constructed from mathematical equations. But where traditional SBI (almost) always requires a pre-determined mechanistic model with a fixed set of equations, where we then only search for parameter values that can produce good simulations, LLMs enable the search in code- and equation-space.
In other words, instead of asking “what are good parameters of the fixed model?”, we can simply ask “what are good models?”
Practically, because LLMs can, and have in some sense been hyper-optimized to write code, a prevailing recipe now is to ask the LLM to directly write down models expressed in code (functions) and then to run that code and evaluate the outcome compared to the target data in the “traditional” manner, then iterate. This is by no means a new idea either, where the classical way to do this might be called “symbolic regression”, i.e., to express model components as a fixed library of elemental functions (e.g., SINDy) and then optimizing their coefficients to fit the data with respect to some distance or “closeness” function.
All that has really changed is that, since LLMs can translate between math and code pretty well, there’s no need to specify the library of expressions a priori anymore. This dramatically opens up the search space because, in principle, the LLM can write whatever math or code it wants. Then at the end of this “search” phase of the loop, it simply runs a single line of code in the terminal, python run_my_program.py, evaluate the outcome against data, then moving onto the next iteration to find a better model, just as you would in traditional optimization and search algorithms.
I’m obviously glossing over a lot of details, especially with how one decides what the next proposed candidate model looks like (surprise, it uses old ideas from evolutionary algorithms), but that’s essentially the high-level recipe behind FunSearch and many other similar agentic model discovery engines in this domain: search-verify-iterate.
Critically, the verification comes in the form of running the program, making sure that 1) the math is legal and the code runs without errors, and 2) the program produces outcomes (model simulations or just function outputs) that are evaluated against the target, whether that’s real experimental data or a reference program’s output. Without the automated, algorithmic verification (i.e., oracle), it would be impossible to take advantage of the generative capabilities offered by LLMs because it would simply take forever for a human to perform the experiments to evaluate each proposed model. Now, it’s just tokens.
This design pattern is not restricted to mechanistic models, even though that’s where AI shines in the physical sciences. The recipe only needs two modules: an LLM, and another thing whose only requirement is to have a fast and algorithmic verifier, either in-built or callable as another tool. So domains like math is great because we have formal verification and a clear sense of right or wrong, and phenomenological models (i.e., not necessarily physics-based) expressable in code also works well.
Some recent examples in neuroscience I really like have adopted this recipe to discover functional models of population tuning in the visual cortex, cognitive models of reward learning and other tasks from human and animal behavior data, and even deep learning models where the goal is simply to be predictive of (simulated) neural data. Unsurprisingly, they all have some kind of ties to Google / DeepMind / FunSearch.
That last one is really interesting because it closes the loop fully, and perfectly illustrates the expanded search space: the pretrained, frozen LLM, powered by deep learning with a fixed architecture (Transformer stacks), is searching over the entire space of deep learning architectures that can fit the data best, where the parameters of the candidate architecture at each iteration are still optimized via the standard gradient-based method. This is identical to Karpathy’s autoresearch idea, just replacing the language modeling objective with a neural-data-prediction objective.
Generalizing to non-differentiable models, what emerges is the optimization-within-optimization-loop pattern (which can also be formulated as probabilistic inference over models): the LLM enables a broader (or “meta”) search-space over all families of functions expressible in equations / code, then regular gradient descent, SBI, or any parameter optimization / inference algorithm that evaluates the quality of a model can then be used to find the best parameters of that specific instantiation of a model to data.
I have high hopes for this recipe, especially for discovering novel mechanistic models of the brain in a data-driven manner, because, as I expressed above, we clearly don’t know what we’re doing but is somehow also limited by our imagination. One potential issue to point out is that this recipe sort of punts the verification problem to the objective or “closeness” function, i.e., how we decide which models are good. In the ML context, there are obvious, even if somewhat legacy choices, like mean-squared-error between prediction and simulation, but is that what we should really optimize to achieve an understanding of the brain?
Lastly, this highlights again the meta-dependence on heldout data as empirical verification, even though within the system there are algorithmic verifiers—it’s not completely opaque like in traditional deep learning without a mechanistic model in the loop, but no matter what, you eventually have to exit the matrix and touch real grass.
Scientific text and code understanding, plus other LLM-assisted tooling
Moving away from equation-based mechanistic models written as programs, we get back to what LLMs were born to do: natural language.
Most scientific knowledge today is still stored and communicated as text in the form of publications (at least for now). Human scientists engage with this literature to understand the state of the art, identify gaps, and produce novel knowledge to fill that gap. Naturally, one hope is that LLMs can also process this text, and of course at a superhuman rate, to similarly identify these gaps for new opportunities. Or, at the very least, to distill from this massive library of human knowledge some manageable nuggets of information that a human scientist can comprehend.
This paper made headlines in the last couple of years, showing that LLMs can predict the outcome of neuroscience experiments better than human neuroscientists. I’m not sure if that says more about AI or human neuroscientists lol. But more seriously, there are some things one can potentially complain about, like the fact that any single human scientist probably have more depth in the literature of their specific subdomain than they know about “general brain research”, which was what the survey evaluated. Or that the LLM is just more consistently picking up subtle statistical regularities in how scientists tend to write about the direction of a finding (trivial example: “However, we show that…”). But the point remains, and is anecdotally backed by our everyday experience of using LLMs in chat mode: they are really good at producing and reasoning over text, and continue to get better at it.
We can also combine scientific text with brain data. Neurosynth (now more than 10 years old) is probably the first, non-AI, organic grassfed machine learning-based natural language-to-brain activation tool that existed. Of course, now we can replace TF-IDF representations with LLM embeddings, either directly interfacing that with brain activation maps through tailored prompts or with some additional post-hoc alignment.
The point is, there are too many papers to read, so just ask an LLM to do it. In that spirit—and even though it’s not as sexy because the AI is not directly “doing” the science—I do believe that the most value we will get out of AI is not fully automated science, but simply as another tool (or set of tools) to make human effort more efficient. So I’m including in this category, in the vein of “help me understand this text”, things like personalized paper digest (like this and this), coding assistants (all LLMs now come with a code interface with tool access), deep research for literature synthesis (all the chat interfaces now include one), in silico rubber duck for project planning (well, it actually talks to you, like this and this), pdf form fillers (just ask Claude Cowork to do it), the list goes on and on. If you’re spending too much time reformatting grants and papers that it’s eating away your research time, use AI to do those things faster so you have more time for science.
In this light, LLMs and the packaged AI tools are not that different from any previous technology-enabled productivity tools, with the caveat that, you still have to check your homework. Coding in particular is worth highlighting again. Evolving novel mechanistic models is still only a very niche (though promising) scientific application of LLMs, whereas wholesale structuring and writing of complex code projects in the context of scientific programming probably remains the most prevalent use case. This article is really worth a read, which emphasizes the design pattern of having a “thinking” agent craft a project plan and the corresponding specification file at an intermediate resolution (e.g. Claude.md context), the execution of that plan by the coding agent, and (the output) of a reference program as an oracle / verifier.
AI (co-)scientist
Finally, combining the last two ideas: if you take a thing that understands, evaluates, and writes scientific text, and another thing that does the technical implementation like writing code for modeling or analyzing numerical data, you’ve essentially replicated the traditional advisor-graduate student relationship.
This paper came out recently that makes progress towards automating AI research. Here’s another recent one on more general scientific research. If you have slightly lower expectations for your AI scientist child, you might call it an intern instead of a full-fledged scientist. If you have the massive expectations of an Asian parent, you might name it AI-Newton. There have been many examples that popped up over the last year or so, and what feels like just as many startups and industry-backed research labs that expand on this concept.

Not much more to say here except that the majority of these applications remain in the computational sciences, and more specifically, in the computer, and as far as I know, none in real neuroscience. The obvious reason for this is that the search-and-evaluate loop for ideas that only involve computer code is bottlenecked by nothing else except how many GPUs you have access to. But again, at some point, you have to come out of the matrix, at least if you’re interested in the brain.
Will AI really help us understand the brain?
I have reached the end of my book, finally.
As you can hopefully appreciate, AI4Neuro, and indeed, AI for any science, is synonymous with the development and application of AI with interpretability, robustness, and understanding in mind—or at least, it should be. On the other hand, the core identity of ML and AI research is one of optimization by whatever means necessary.
But do we have good metrics we can optimize for and use to verify understanding? Remains to be seen, but certainly, mean-squared-error probably ain’t it.
In any case, whatever predictions from novel models discovered by AI-enabled co-scientists will at some point have to be validated in vivo, out in the real world. Consider doing your PhD in an experimental lab for the next few years.
Much of what I’ve written is regurgitating insights people have realized about the systems in general, like the need for verification, or the “jagged frontier” of LLMs where they’re truly outstanding at some tasks (like coding) and shit the bed in others (like producing images with text). I follow Ethan Mollick and Simon Willison’s newsletters (highly, highly recommend), where in the latter, this recent Karpathy tweet was brought up:

One last interesting point here is that, the recent and very rapid advances in model capability for doing real work (like coding) is very much a product of the second point: revenue generation potential for organizational-scale subscribers. This is obviously never going to be science, much less neuroscience, unless you’re doing something so vague that it plausibly solves intelligence and consciousness in one go so that some rich guy somewhere (and without fail, it’s usually a guy) thinks this will make 1000x returns.
Other than that, science, and certainly neuroscience—as amazingly cool and critical as it is for society—is really still on the fringes of AI development. Everything we can do with AI for science takes advantage of a lucky coincidence: scientists sometimes write code too. This means frontier-scale AI development will almost never have science explicitly in mind, which is fine, except that the tools and technology we have very much shape what science we do, and how.
We already start to see this shaping, and in particular, funneling research ideas. This is very, very not good for a field like neuroscience, at a stage before we even know what good questions are. But as the article above finds, there are strong social and career incentives to use AI. I’m guilty of this as well, of course, for the exact half-joke reason I started with.
AI is hot, and we’re currently at a stage where having AI produce very run-of-the-mill work (like 1 paper acceptance in 3 tries at an ICLR workshop that usually has a >75% acceptance rate) is enough to get published in Nature just because “the AI did it all by itself (but-not-really-because-it-still-needs-a-ton-of–handholding!!)”
So here is my final prediction to end this trilogy: when AI has really helped us understand something about the brain, it will not be a big deal because AI did it, but because the science is truly groundbreaking.
In other words: we will have achieved success when our ‘AI co-scientist’ is no longer the headline, but just another paragraph buried in the Methods section.